📝 Paper Summary
Continual Learning
Multimodal Pretraining
Foundation Models
The paper introduces FoMo-in-Flux, a benchmark for continual multimodal pretraining, demonstrating that simple finetuning coupled with model merging outperforms specialized continual learning methods under realistic compute constraints.
Core Problem
Multimodal foundation models become outdated as new domains and concepts emerge, but current continual pretraining research focuses on extreme cases (large-scale updates or tiny edits) rather than practical, minor updates.
Why it matters:
- Real-world applications require adapting to specific subdomains (e.g., medical, synthetic) over a model's lifecycle without retraining from scratch
- Existing benchmarks like TiC-RedCaps are too noisy and monolithic, while traditional Continual Learning benchmarks (Split-ImageNet) lack the scale and modality of foundation models
- Practitioners lack guidance on how compute budgets, data stream ordering, and method choices affect the trade-off between learning new tasks and retaining zero-shot capabilities
Concrete Example:
A deployed vision-language model might need to adapt sequentially to 'ruins', 'industrial areas', and 'bird species'. Naive finetuning forgets previous concepts (catastrophic forgetting), while parameter-efficient methods (LoRA) often struggle to learn the new data effectively (plasticity issues) under strict compute limits.
Key Novelty
FoMo-in-Flux Benchmark & Memory-Adjusted FLOPs (MAFs)
- Constructs a controlled data stream from 63 diverse datasets (natural, synthetic, fine-grained) with high-quality captions, enabling precise study of concept ordering effects
- Introduces Memory-Adjusted FLOPs (MAFs) to enforce realistic compute budgets that account for both operation count and peak memory usage, leveling the playing field between methods
- Demonstrates that model merging (averaging weights of old and new models) is a superior strategy for 'minor' continual updates compared to standard continual learning or LoRA
Architecture
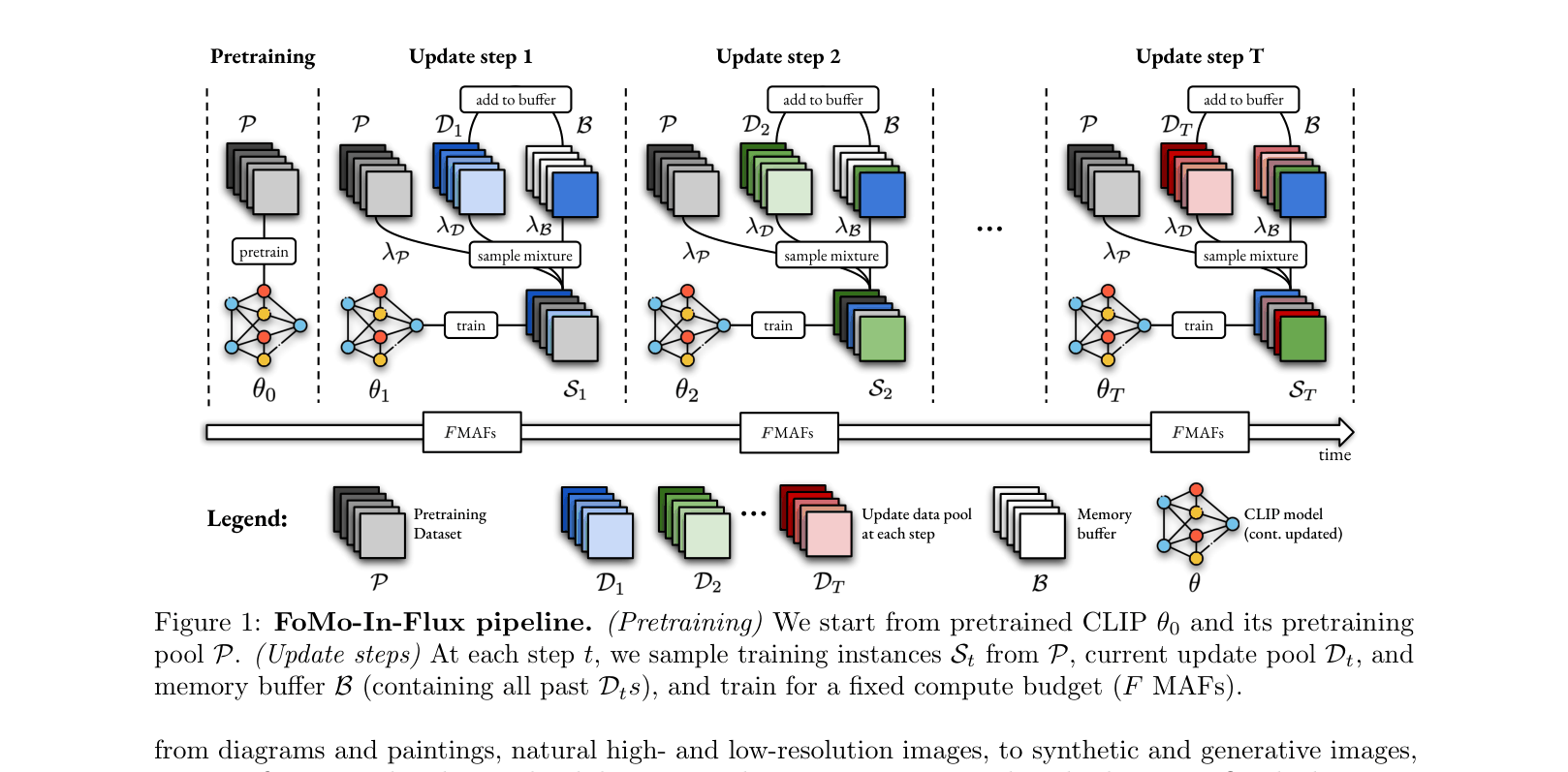
The FoMo-in-Flux pipeline: Pretraining -> Sequential Updates -> Evaluation. Shows the data mixing strategy and iterative update process.
Evaluation Highlights
- Model Merging (averaging finetuned and zero-shot weights) achieves the best trade-off, maintaining high Zero-Shot Retention (>68%) while significantly improving Knowledge Accumulation (>55%) compared to LoRA or full finetuning
- Parameter-efficient methods like LoRA and VeRA suffer from plasticity issues, failing to learn new tasks as effectively as full finetuning under the same compute budget
- Replaying previous adaptation data is more critical than replaying pretraining data; the specific choice of pretraining data pool (e.g., LAION vs CC-3M) significantly impacts zero-shot retention
Breakthrough Assessment
8/10
Provides a comprehensive, practically grounded benchmark that challenges prevailing wisdom about parameter-efficient methods in continual learning, offering a clear 'practitioner's guide' and a new metric (MAFs).