📊 Experiments & Results
Evaluation Setup
Pretrain on IG-3B, then transfer to various downstream tasks via finetuning, linear probing, or zero-shot transfer (via LiT).
Benchmarks:
- ImageNet-1k (IN1k) (Image Classification)
- iNaturalist-18 (iNat18) (Fine-grained Classification)
- LVIS (Long-tailed Object Detection)
- Kinetics-400 (K400) (Video Action Recognition)
Metrics:
- Top-1 Accuracy
- AP (Average Precision) for box/mask
- 1-shot / 5-shot Accuracy
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Classification results on ImageNet-1k and iNaturalist-18 showing the scaling behavior of MAE->WSP (MAWS). | ||||
| ImageNet-1k | Top-1 Accuracy | 88.6 | 89.3 | +0.7 |
| iNaturalist-18 | Top-1 Accuracy | 81.1 | 82.3 | +1.2 |
| ImageNet-1k | Top-1 Accuracy | 85.8 | 87.0 | +1.2 |
| Low-shot classification results demonstrating the label efficiency of the pre-pretrained representations. | ||||
| ImageNet-1k (1-shot) | Top-1 Accuracy | 59.4 | 57.1 | -2.3 |
| ImageNet-1k (1-shot) | Top-1 Accuracy | Not reported in the paper | 63.6 | Not reported in the paper |
| LVIS | AP_box | 47.1 | 50.8 | +3.7 |
Experiment Figures
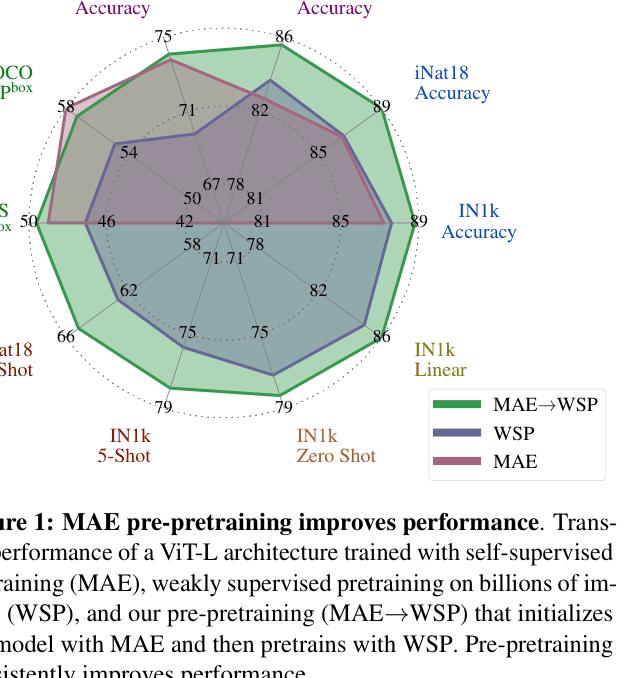
Transfer performance of ViT-L trained with MAE, WSP, and MAE->WSP across 10 tasks.
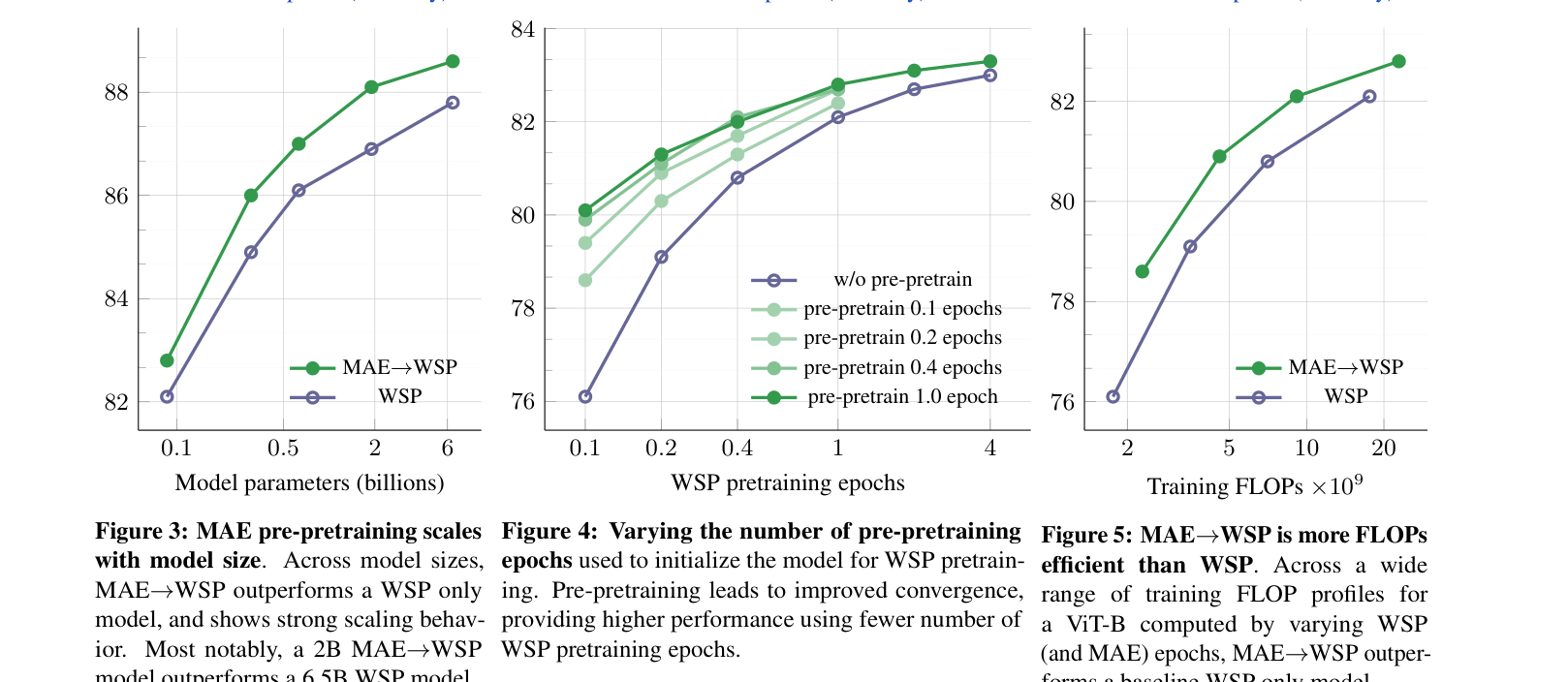
Scaling behavior of MAE->WSP vs WSP for models ranging from 0.1B to 6.5B parameters.
Main Takeaways
- MAE pre-pretraining scales with dataset size (Instagram-3B vs ImageNet-1k) and model size (up to 6.5B parameters), contrary to prior beliefs that MAE only scales with model size.
- Pre-pretraining consistently improves convergence speed; a model pre-pretrained for 0.1 epochs matches the performance of a randomly initialized model trained for significantly longer.
- The method is particularly effective for transfer tasks like object detection (LVIS) and low-shot classification, where pure weakly supervised pretraining often underperforms.
- A 2B parameter model using MAE->WSP outperforms a 6.5B parameter model using only WSP, highlighting parameter efficiency gains.