📝 Paper Summary
Physics Foundation Models
Physics Emulation
Representation Learning
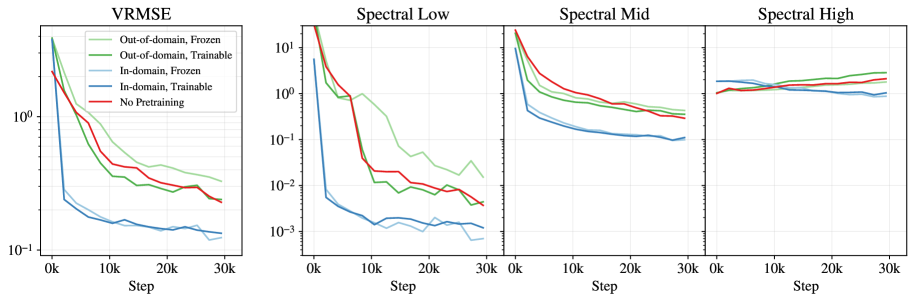
Pretraining the tokeniser (encoder-decoder) before training the dynamics model significantly improves efficiency and accuracy for physics emulation, provided the pretraining data aligns physically with the downstream task.
Core Problem
Training physics foundation models from scratch is computationally expensive because learning compact data representations (tokenisation) and complex dynamics simultaneously impedes the effectiveness of both processes.
Why it matters:
- High-resolution scientific simulations produce vast data volumes that are computationally prohibitive to model directly in pixel space with transformers
- Current approaches often train tokenisers and dynamics models jointly from scratch, contrasting with computer vision where pretrained tokenisers are standard
- Practitioners with limited compute resources struggle to train effective emulators without efficient initialization strategies
Concrete Example:
When training a rollout model for fluid dynamics (Euler equations) from scratch, the model struggles to capture low-frequency structures early on. In contrast, using a tokeniser pretrained on the same Euler data reduces error by 64% after just 10,500 steps.
Key Novelty
Systematic evaluation of Tokeniser Pretraining for Physics
- Decouples the learning of spatial representations (tokeniser) from temporal dynamics (processor), allowing each to be optimized more effectively
- Demonstrates that 'in-domain' pretraining (same physics) yields massive gains, while 'out-of-domain' (different physics) offers smaller benefits
- Introduces flexible spatiotemporal compression that allows runtime adjustment of token coarseness to handle different physical regimes without retraining
Architecture
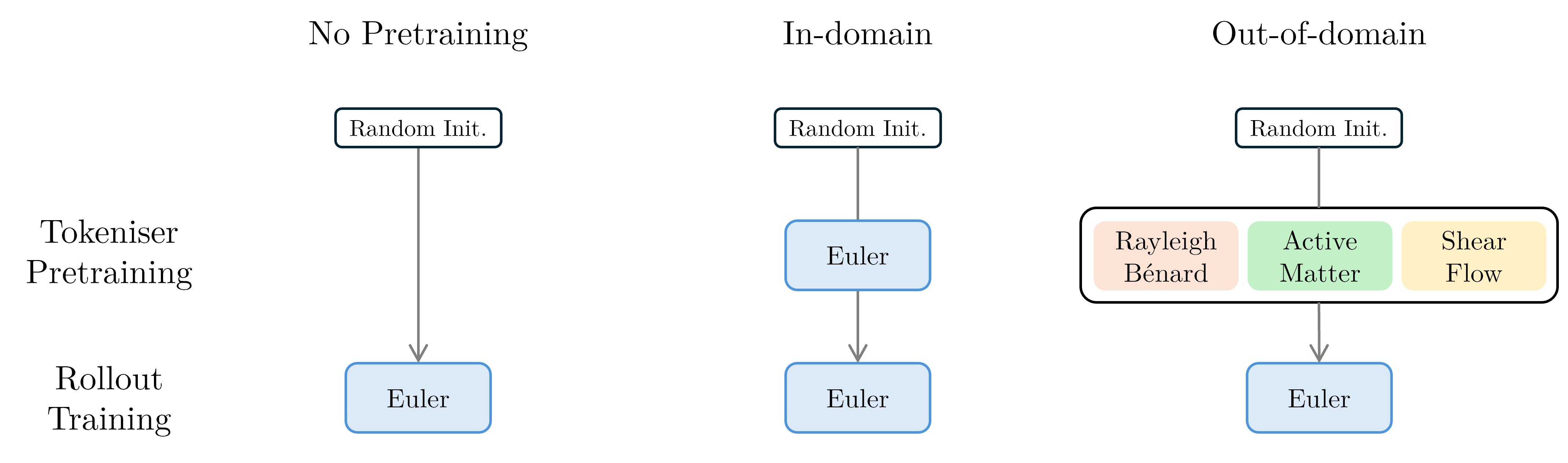
Schematic of the training setup comparing 'From Scratch' vs 'Pretrained' approaches.
Evaluation Highlights
- In-domain pretraining reduces spatial error (VRMSE) by 64% (0.439 → 0.158) compared to training from scratch after 10.5k steps
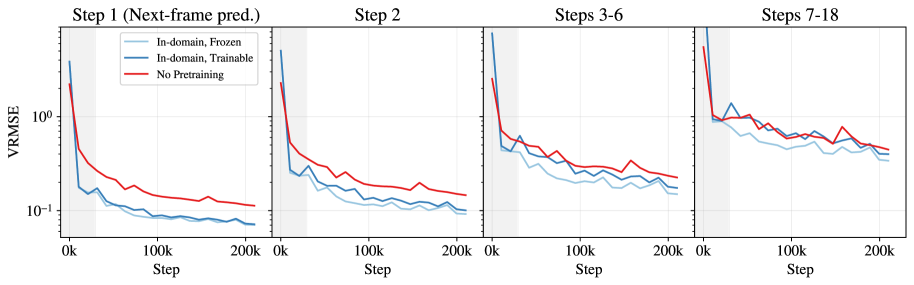
- Freezing a pretrained tokeniser (updating only 2% of parameters) matches the performance of a fully trainable one for short horizons
- For long rollouts (7-18 steps), the frozen tokeniser strategy outperforms the fully trainable approach, acting as a regularizer against error accumulation
Breakthrough Assessment
7/10
Provides the first systematic empirical evidence justifying separate tokeniser pretraining for physics models—a standard in vision but previously assumed in physics. The flexible compression mechanism adds practical utility.