📝 Paper Summary
Pretraining dataset creation
Data curation and filtering
Data mixing and sampling
This paper systematically ablates the pretraining data pipeline—curation, selection, and sampling—and demonstrates that leveraging granular data attributes like quality and domain significantly improves downstream model performance.
Core Problem
Leading language model developers do not disclose their pretraining data construction methods, leaving the community without actionable guidelines on how to curate, select, and sample data effectively.
Why it matters:
- Pretraining datasets are the primary driver of recent LM capabilities (e.g., GPT-4, Gemini), yet recipes remain trade secrets
- Ineffective data filtering (e.g., aggressive toxicity removal) can inadvertently discard high-quality text, degrading model performance
- Standard heuristics for data sampling often fail to balance diverse domains effectively compared to systematic approaches
Concrete Example:
When filtering for toxicity, a naive classifier might remove news articles about 'sensitive subjects' (e.g., war, protests) because they contain toxic words. This paper shows these documents are often high quality; removing them degrades performance. Using a target set of 'Low Toxicity, High Quality' retains these valuable documents.
Key Novelty
Systematic Pretraining Pipeline Ablation & Attribute-Aware Construction
- Conducts the first large-scale ablation study across the entire pretraining pipeline (curation, selection, sampling) rather than just one component
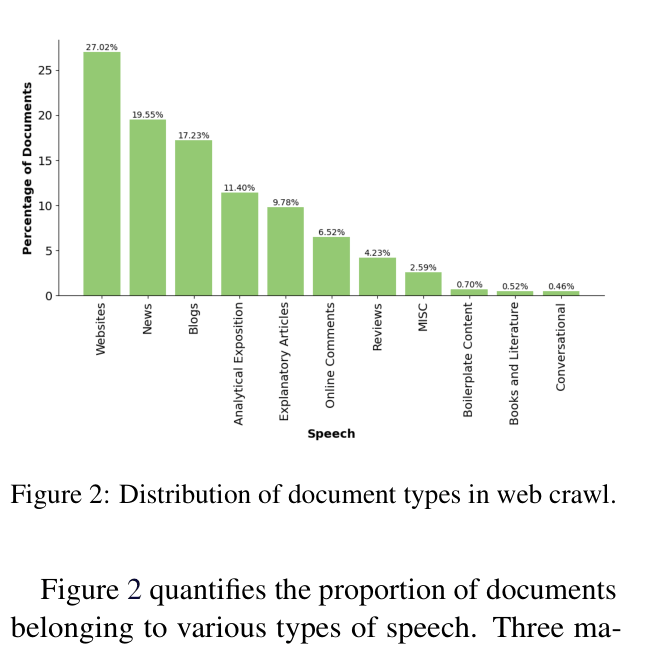
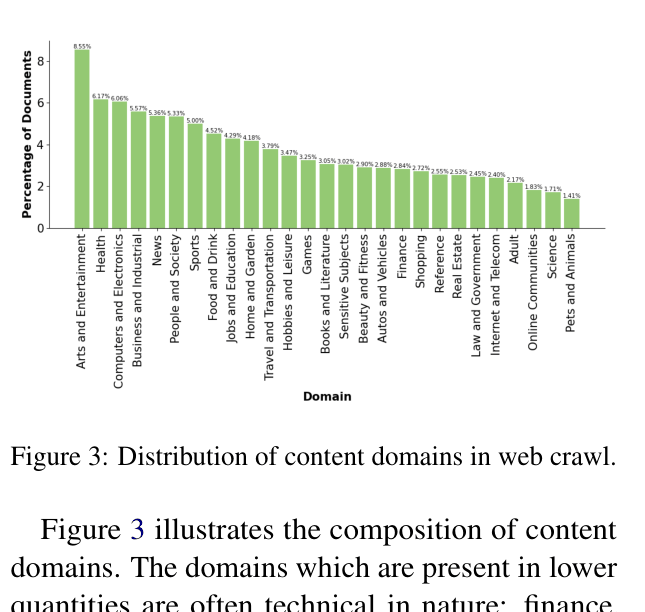
- Analyzes 90+ Common Crawl snapshots to categorize web data by domain, quality, and speech type, revealing that technical domains are scarce while news/blogs dominate
- Proposes using these attribute labels to create fine-grained sampling buckets, improving model accuracy over standard source-based sampling
Architecture
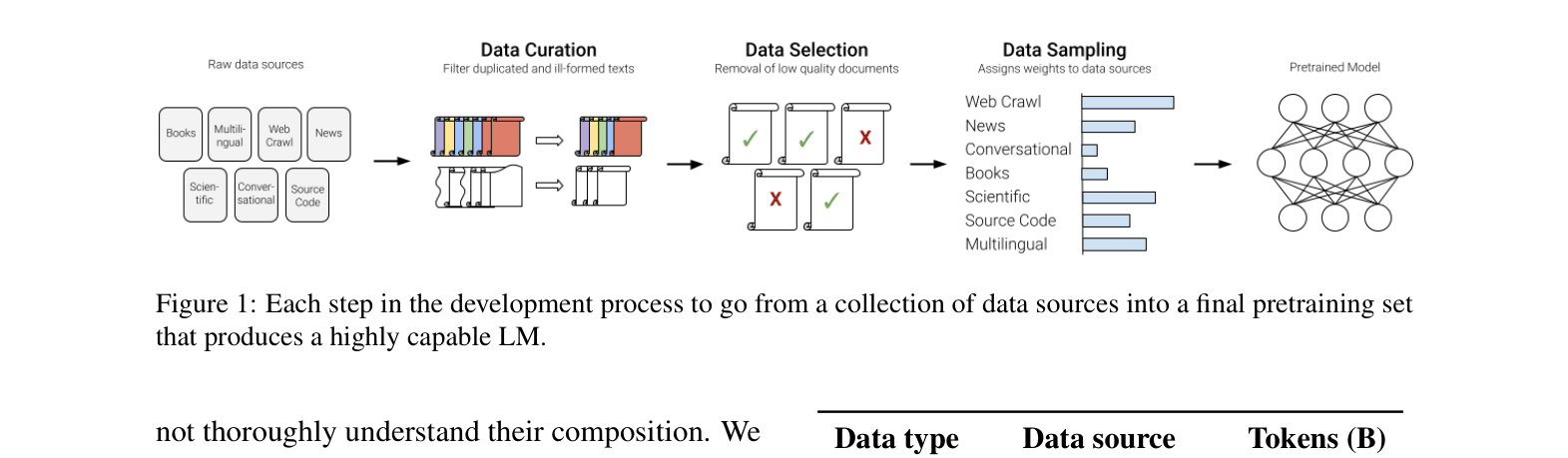
The complete pretraining dataset development pipeline
Evaluation Highlights
- +1.29 average accuracy improvement on English benchmarks using UniMax sampling compared to preference-based weighting
- +1.07 accuracy improvement using fine-grained Quality-based sampling buckets compared to a baseline without attribute information
- Prioritizing older documents during deduplication outperforms random selection by +0.51 points
Breakthrough Assessment
8/10
Provides a rare, comprehensive empirical guide to pretraining data construction with actionable recipes, addressing a major transparency gap in the field.