📝 Paper Summary
Continued Pretraining
Synthetic Data Generation
Knowledge Injection
To teach language models knowledge from small corpora, this paper proposes generating a massive synthetic dataset by prompting a stronger model to describe relations between entities extracted from the source documents.
Core Problem
Pretrained models struggle to learn facts from small, domain-specific corpora (like a single textbook) because effective knowledge acquisition requires training on hundreds of diverse representations of the same fact, which small static datasets lack.
Why it matters:
- Current methods require massive internet-scale data for knowledge acquisition, making it difficult to adapt models to private or niche domains with limited text
- Simple paraphrasing of small datasets fails to provide the necessary diversity for the model to generalize and retain the information
- As public data is exhausted, future improvements will rely on learning from the 'tails' of the data distribution (rare/niche documents)
Concrete Example:
Directly training a model on a linear algebra textbook fails because the concepts appear too few times. EntiGraph solves this by extracting entities like 'Vector' and 'Linear space' and generating diverse synthetic 'notes' about their relationships, simulating the variety found in online discussions.
Key Novelty
EntiGraph (Entity-centric Synthetic Augmentation)
- Instead of simply paraphrasing sentences, the method constructs a 'knowledge graph' by extracting entities from the source
- It then prompts an LLM to generate diverse text descriptions for specific pairs or triplets of entities, explicitly 'filling in' the edges of the graph to create new, diverse contexts for the same facts
Architecture
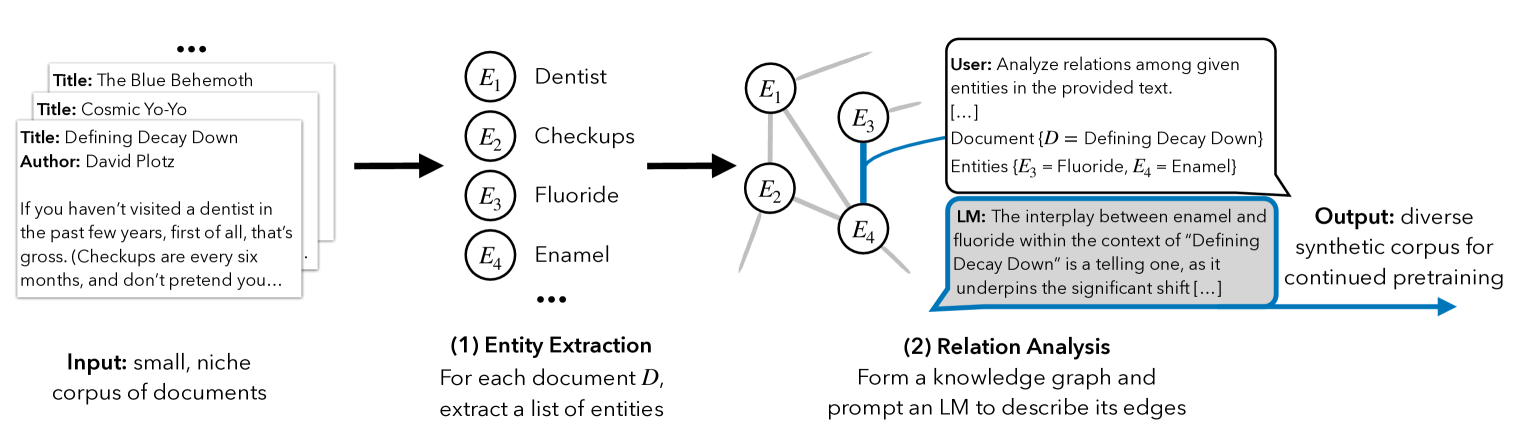
The EntiGraph data augmentation pipeline process.
Evaluation Highlights
- Synthetic continued pretraining with 455M EntiGraph tokens recovers 80% of the accuracy gain achievable by providing the source documents at inference time (RAG)
- Achieves a log-linear scaling trend in Question Answering accuracy as the number of synthetic tokens increases up to 455M
- Outperforms standard continued pretraining on original documents and simple paraphrasing baselines
Breakthrough Assessment
8/10
Offers a practical, scalable solution to the 'small corpus' learning problem. The log-linear scaling finding and the approach of externalizing diversity via graph traversal are significant methodogical contributions.