📝 Paper Summary
Time Series Forecasting
Foundation Models for Time Series
Transfer Learning
The paper proposes a supervised contrastive learning framework that pretrains a model to distinguish between different time series datasets, then uses probability estimates of dataset similarity to guide finetuning on target data.
Core Problem
Training foundation models for time series is difficult because pretraining datasets often have vastly different dynamics from target finetuning datasets, leading to poor transfer performance.
Why it matters:
- Standard foundation models struggle to adapt to heterogeneous collections of time series data where dynamics vary significantly between domains (e.g., electricity vs. traffic).
- Existing approaches often fail to explicitly leverage the relationships between the pretraining source domains and the specific target domain during the finetuning phase.
Concrete Example:
A model pretrained on electricity data might fail to predict traffic flow accurately because the underlying temporal dynamics are different. The paper shows that without guidance, a pretrained model can have high error on Electricity data (0.247 MSE) compared to specialized models.
Key Novelty
Similarity-Guided Supervised Contrastive Finetuning
- Pretrains an encoder using supervised contrastive learning where 'labels' are the dataset identities, teaching the model to distinguish features from different source datasets.
- Derives a probabilistic similarity metric that estimates how likely a target sample belongs to each pretraining dataset based on representation proximity.
- Finetunes the model using this probability to weight positive/negative pairs: target samples are pulled closer to representations of similar pretraining datasets and pushed away from dissimilar ones.
Architecture
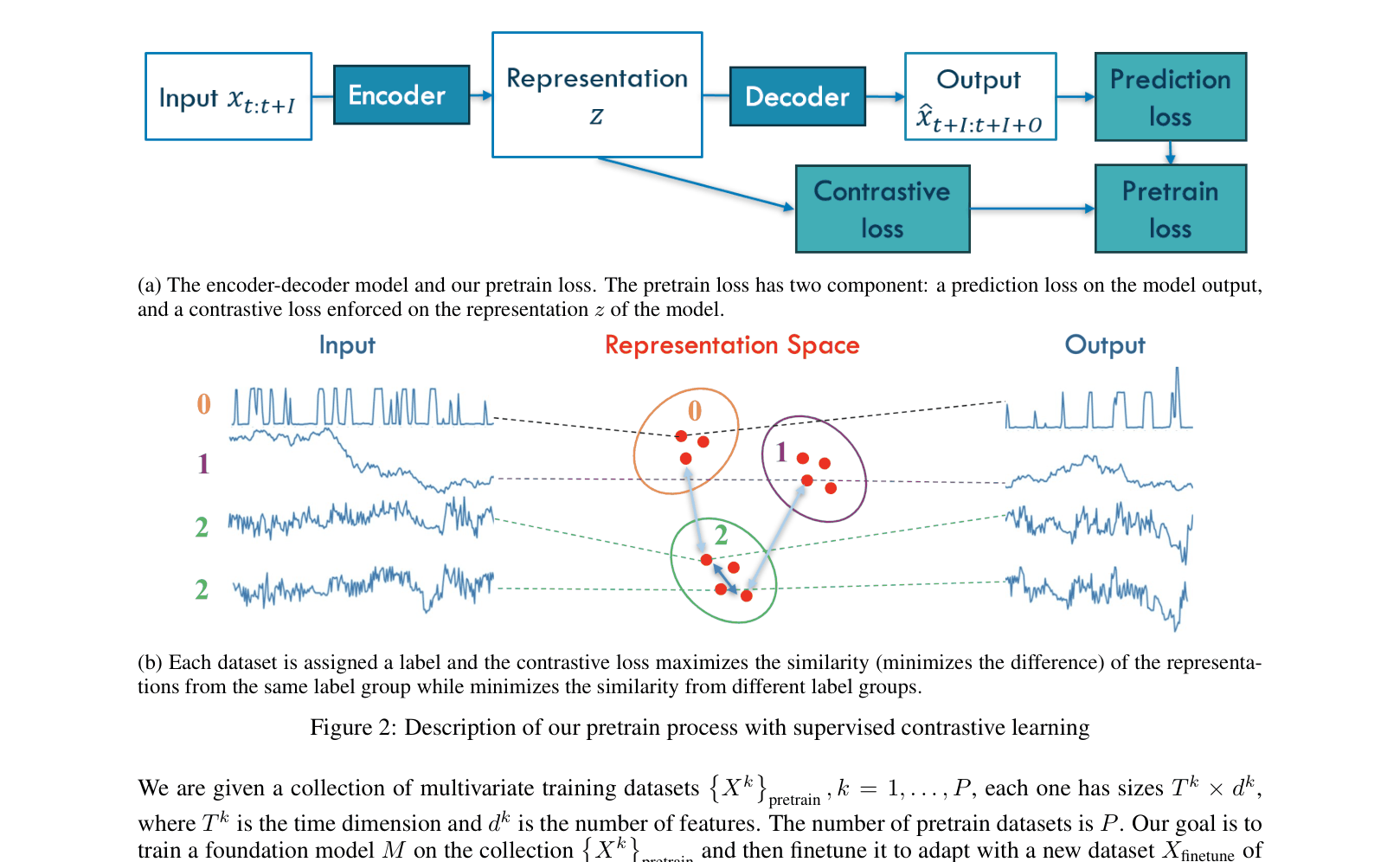
Diagram of the pretraining process using supervised contrastive learning. Shows the encoder-decoder structure and how contrastive loss is applied to representations using dataset labels.
Evaluation Highlights
- Finetuned model achieves 0.269 MSE on Exchange-Rate dataset (average over 4 horizons), outperforming the TimesNet baseline (0.282 average) and all other supervised methods.
- On ETTh1, the finetuned model achieves 0.446 average MSE, surpassing TimesNet (0.476 average).
- Pretraining enables accurate dataset identification: the model correctly identifies Exchange-Rate samples with 87.79% probability, correlating with strong downstream performance.
Breakthrough Assessment
5/10
Proposes a logical extension of contrastive learning to time series domain adaptation. Results are mixed: outperforms baselines on some datasets (Exchange, ETTh1) but underperforms on others (Traffic, Weather, ETTh2). Evaluation uses simple linear backbones.