📝 Paper Summary
Medical Imaging (CT)
Video Pretraining
3D Deep Learning
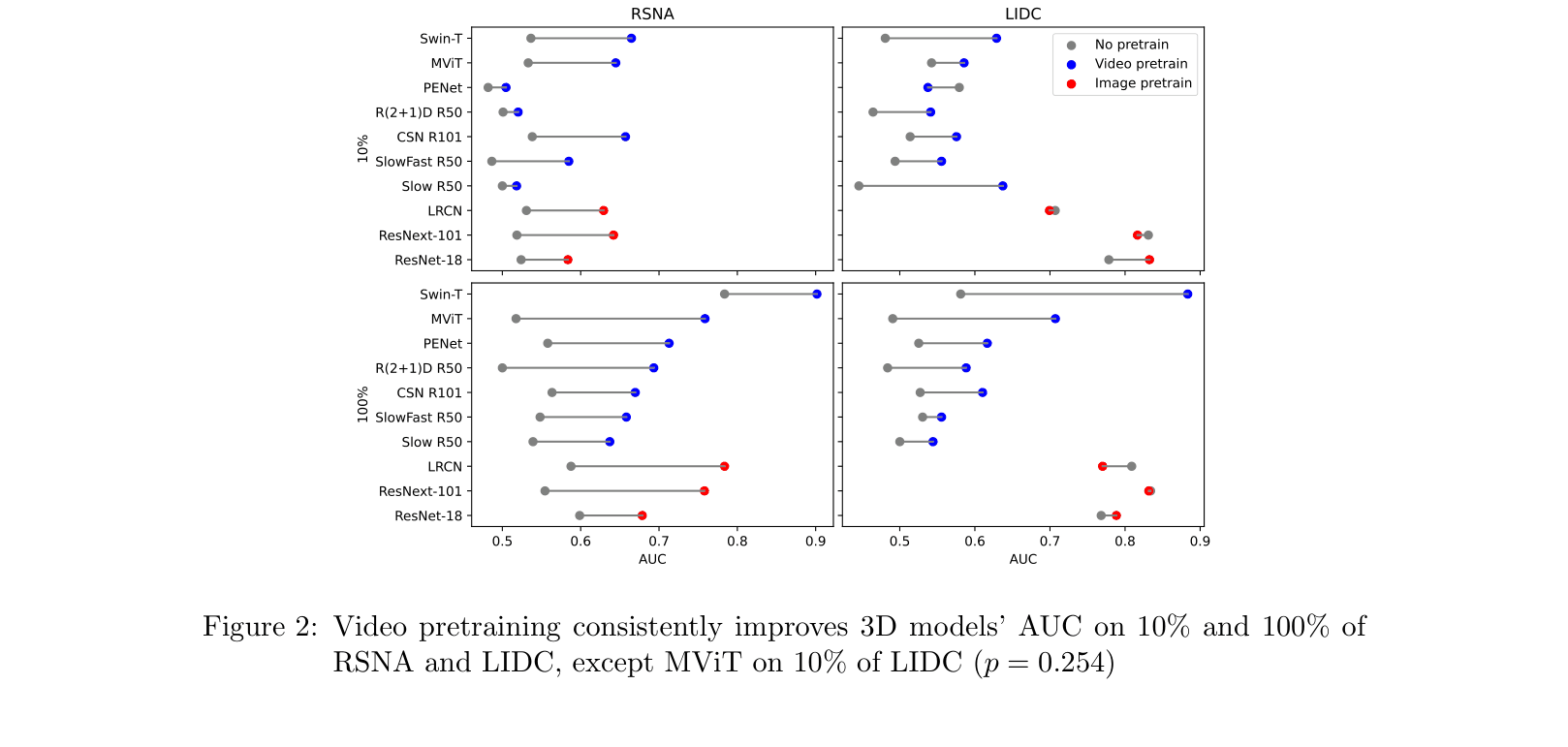
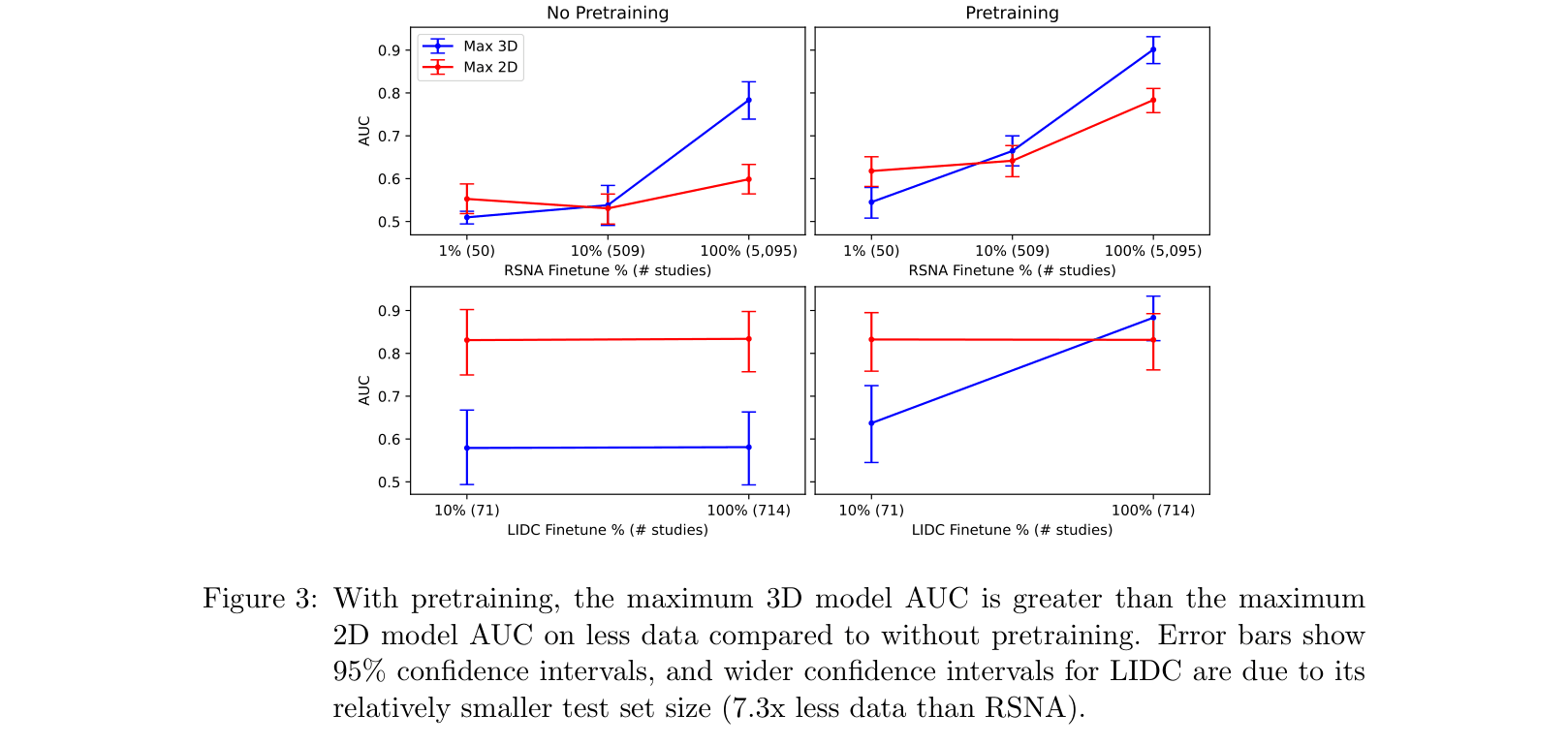
Pretraining 3D models on large-scale natural videos (Kinetics-400) significantly improves performance on 3D chest CT tasks, enabling them to outperform 2D baselines even on small datasets.
Core Problem
3D medical imaging tasks lack standard large-scale pretraining datasets (like ImageNet for 2D), causing practitioners to rely on 2D models that ignore native 3D/temporal information.
Why it matters:
- 3D medical datasets are small and expensive to curate, making models prone to overfitting without effective pretraining
- Current approaches adapting 2D ImageNet weights to 3D models fail to capture cross-sectional anatomical relationships
- 2D models remain the de-facto standard in medical imaging despite losing volumetric context, stifling the adoption of more capable 3D architectures
Concrete Example:
A 2D ResNet processes a CT scan slice-by-slice, missing the continuity of a blood vessel across slices. A 3D model trained from scratch on small medical data overfits. This paper shows a 3D model pretrained on YouTube action videos (e.g., 'playing darts') learns spatiotemporal features that transfer effectively to tracking vessels in 3D CT scans.
Key Novelty
Transfer Learning from Natural Video to 3D Medical Imaging
- Leverage the structural similarity between the time dimension in videos and the depth (z-axis) dimension in CT scans to learn spatiotemporal features
- Systematic evaluation across seven 3D architectures and two distinct clinical tasks proves video pretraining is a universal booster, not just a model-specific trick
- Demonstrates that large-scale out-of-domain pretraining (YouTube videos) is more effective than smaller-scale in-domain pretraining (CT scans) for 3D models
Architecture
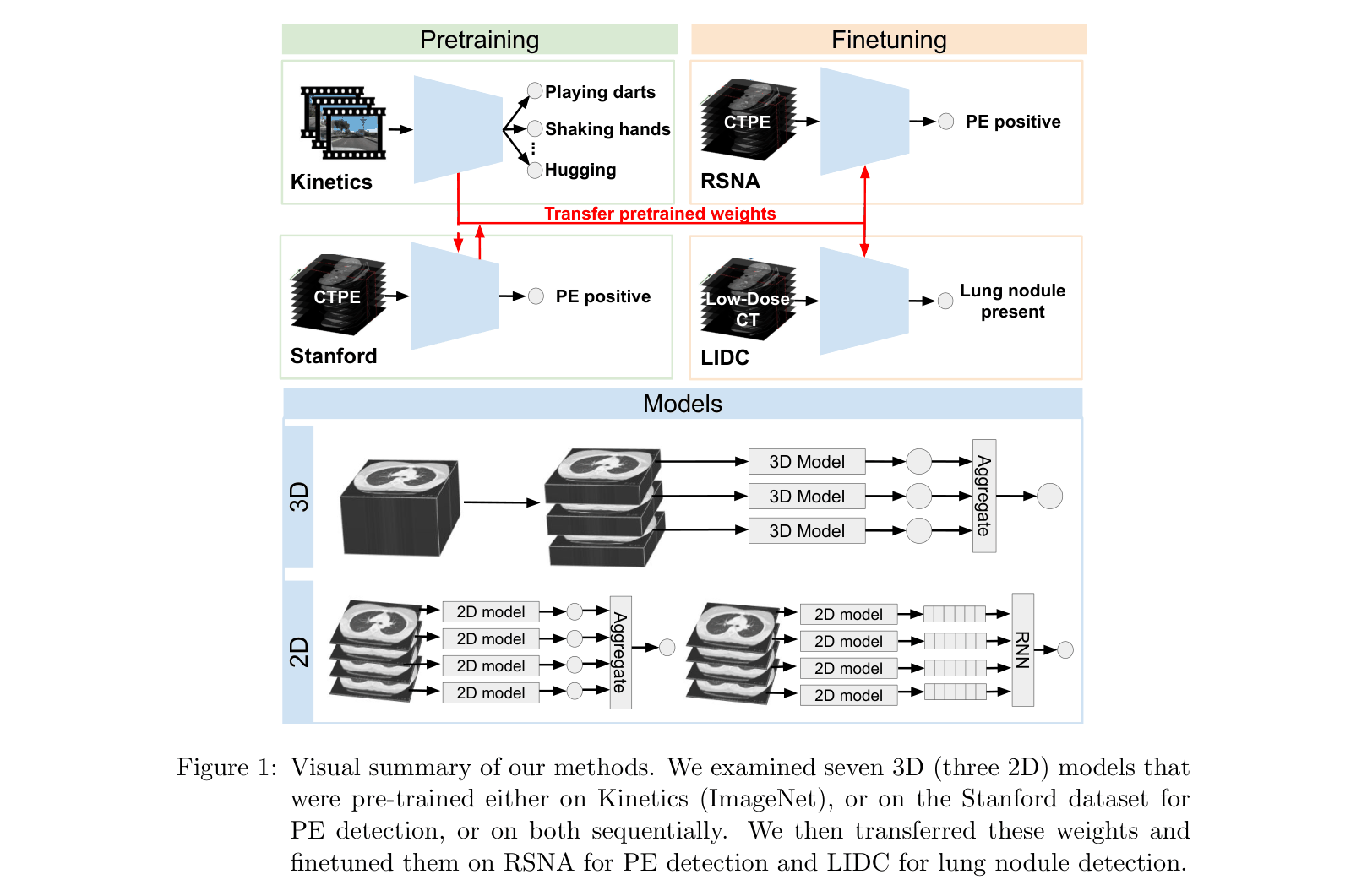
Conceptual workflow of the pretraining and finetuning strategies
Evaluation Highlights
- +0.146 AUC improvement on average for 3D models on PE detection when pretrained on video vs. training from scratch
- Video-pretrained Swin-T outperforms the best 2D baseline (LRCN) by +0.118 AUC on RSNA PE detection
- Video pretraining on Kinetics-400 outperforms in-domain pretraining on Stanford CTs by +0.182 mean AUC on PE detection
Breakthrough Assessment
8/10
Strongly challenges the dominance of 2D models in medical imaging by providing a proven recipe (video pretraining) to make 3D models effective, even with limited medical data.