📝 Paper Summary
Language Model Alignment
Pretraining Objectives
Aligning language models with human preferences during pretraining via conditional training is more effective and robust than the standard practice of pretraining on raw data followed by finetuning.
Core Problem
Standard language models are pretrained to imitate internet text, essentially baking in undesirable behaviors (toxicity, PII leaks, bad code) that are difficult to fully remove during later finetuning.
Why it matters:
- Models trained on raw data learn to imitate falsehoods, offensive comments, and buggy code, which violates safety and utility goals.
- Post-hoc alignment (filtering, RLHF) struggles because large models resist forgetting their training data; filtering data beforehand severely reduces data quantity and diversity.
Concrete Example:
When prompted with a toxic start, a standard MLE-pretrained model often continues with toxicity because it learned to imitate such patterns. Even after finetuning, models can be 'jailbroken' to reveal this underlying behavior.
Key Novelty
Pretraining with Human Feedback (PHF)
- Instead of filtering bad data, keep it but tag it: pretrain the model on the full distribution but condition it on the 'quality' or 'safety' score of the text segments.
- Use a reward function (e.g., toxicity classifier) to label text segments as <|good|> or <|bad|> during pretraining, allowing the model to learn world knowledge from all data while learning to generate only high-reward text at inference.
Architecture
Conceptual comparison of Conventional Pretraining, Pretraining with Feedback (PHF), and Finetuning. While not a circuit diagram, it illustrates the training flow and results.
Evaluation Highlights
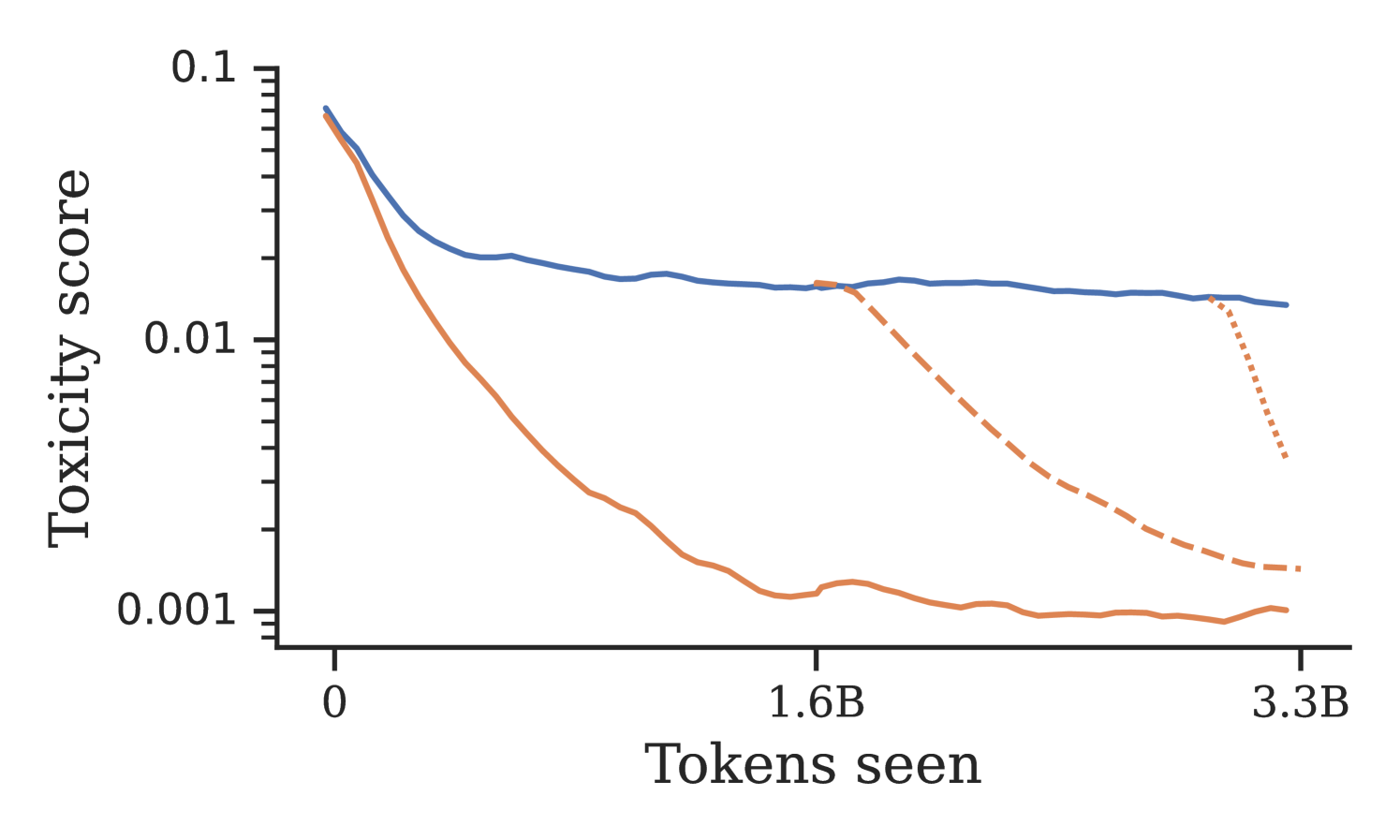
- Conditional training reduces the rate of undesirable content by up to an order of magnitude compared to standard pretraining (MLE).
- Pretraining with feedback (PHF) outperforms the standard recipe of MLE pretraining followed by finetuning with feedback, achieving lower toxicity and PII rates.
- Conditional training maintains downstream capabilities (GLUE, zero-shot tasks) comparable to standard MLE models, unlike filtering which harms performance.
Breakthrough Assessment
8/10
Challenges the dominant paradigm of 'pretrain then align' by showing that alignment should happen *during* pretraining. Simple method (conditional training) yields Pareto-optimal results.