📝 Paper Summary
Reinforcement Learning (RL)
Imitation Learning
Robotic Manipulation & Locomotion
Actor-Critic Pretraining (ACP) improves RL sample efficiency by initializing the critic network using rollouts from a behaviorally cloned actor, rather than initializing only the actor.
Core Problem
Deep Reinforcement Learning (RL) is highly sample-inefficient and prone to unsafe exploration, and standard pretraining methods (Behavioral Cloning) typically ignore the critic network.
Why it matters:
- RL requires millions of interactions, causing physical wear and time costs in real-world robotics
- Standard actor-only pretraining often leads to 'catastrophic forgetting' where performance drops initially because the randomly initialized critic provides poor guidance
- Existing solutions like PIRL (Pretraining with Imitation and RL fine-tuning) can be unstable or slow to improve beyond the expert baseline
Concrete Example:
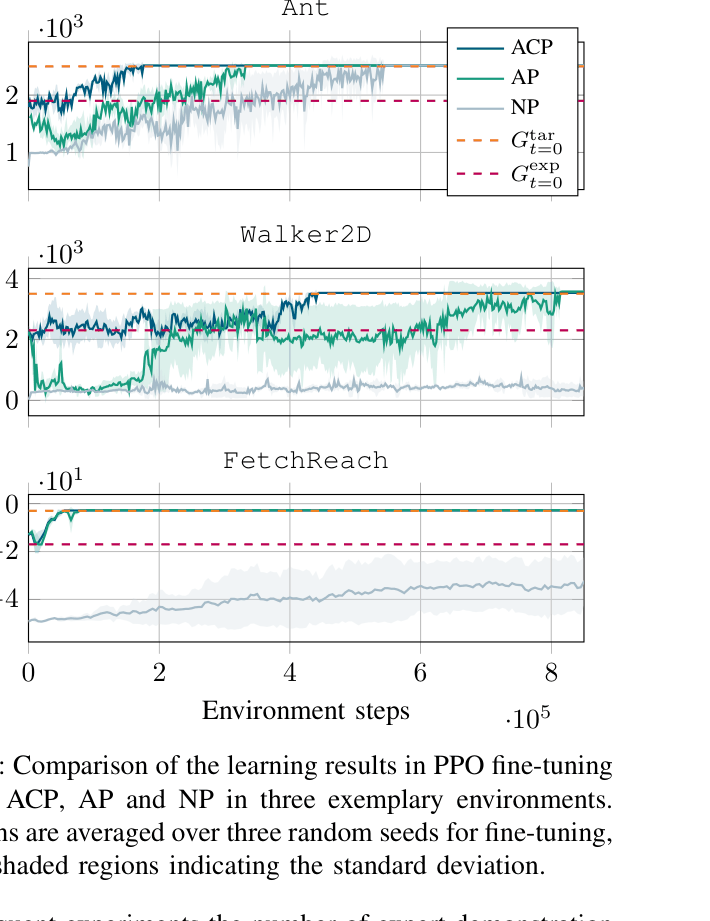
In the Walker2D task, standard PPO fails to reach the target return within the training budget. Actor-only pretraining suffers an initial performance crash (catastrophic forgetting) before recovering. ACP avoids this crash and converges significantly faster.
Key Novelty
Actor-Critic Pretraining (ACP) with Residual Architecture
- Pretrains the actor via Behavioral Cloning on expert data, then freezes it to generate rollouts
- Pretrains the critic using the returns from these specific rollouts (ensuring value estimates match the pretrained policy's behavior)
- Uses a residual actor architecture where the backbone is frozen during fine-tuning but a residual connection allows the decision head to adapt, preventing the loss of expert 'instincts'
Architecture
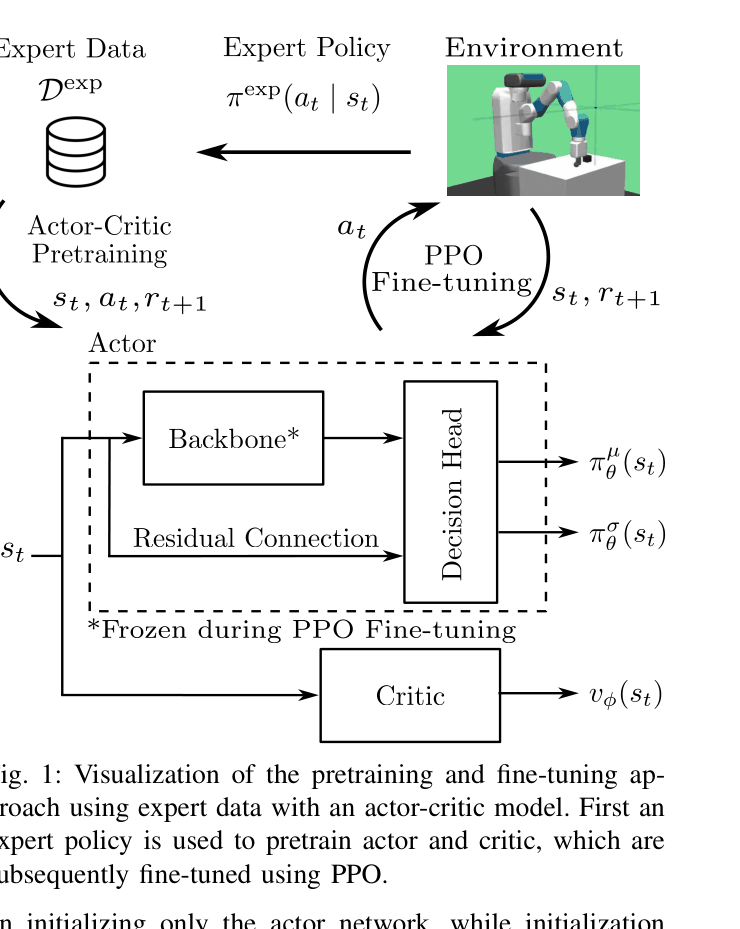
Conceptual flow of the pretraining and fine-tuning approach, showing the separation of Actor and Critic initialization.
Evaluation Highlights
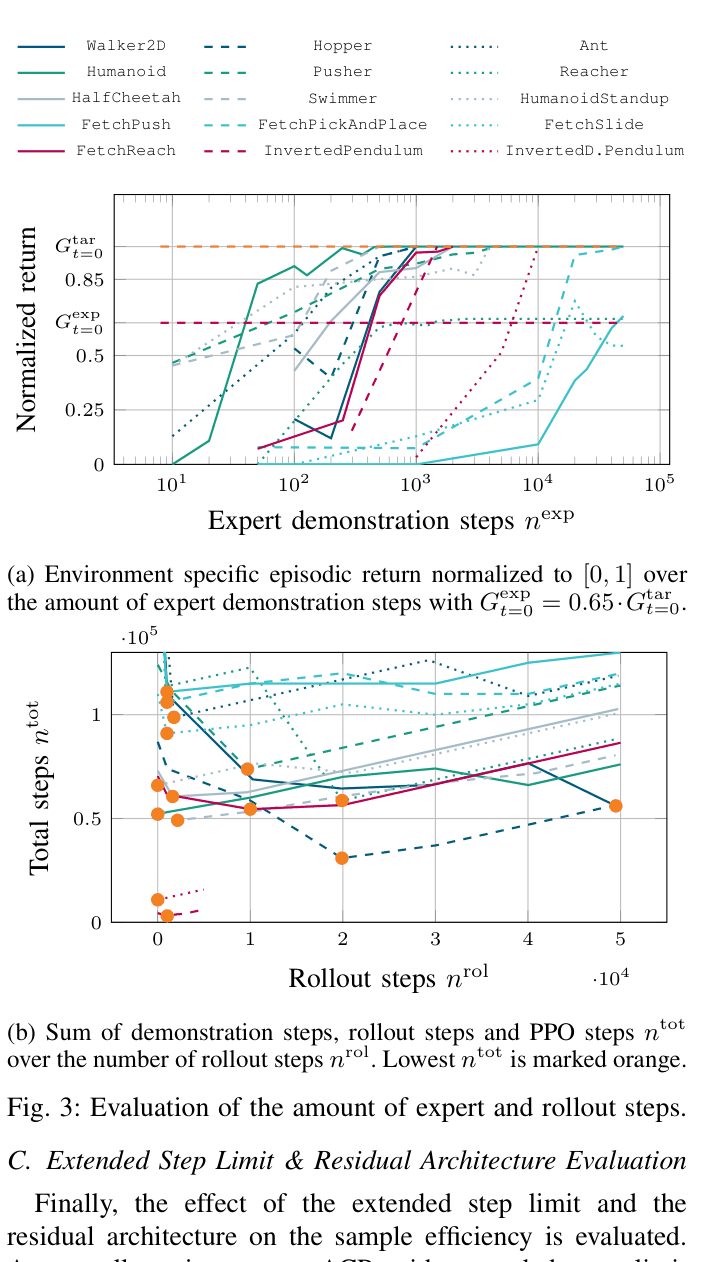
- 86.1% average reduction in environment steps compared to PPO with no pretraining across 15 tasks
- 30.9% average reduction in environment steps compared to standard Actor-Only Pretraining (AP)
- Mitigates catastrophic forgetting in complex environments like Ant and Walker2D where Actor-Only Pretraining initially degrades performance
Breakthrough Assessment
7/10
Solid empirical improvement (30%+) over strong baselines (Actor-Only Pretraining) in standard benchmarks. Addresses a clear logical gap (critic initialization) with a straightforward method. Limited to simulated robotics so far.