📝 Paper Summary
Self-Supervised Learning (SSL)
Continued Pretraining / Domain Adaptation
Difference-Masking improves continued pretraining by selectively masking concepts that make a target domain different from the general pretraining domain, rather than masking randomly.
Core Problem
Standard masked language modeling randomly selects tokens to mask, but this strategy ignores the intuition that some concepts are more critical for learning a specific domain than others.
Why it matters:
- Random masking forces models to spend capacity reconstructing trivial or domain-irrelevant words (e.g., 'the', 'process') rather than key domain concepts.
- Effective domain adaptation is crucial when target domains (like chemistry or medical texts) differ substantially from general pretraining data.
- Existing selective masking approaches often rely on supervised labels or domain-specific entity taggers which are not always available.
Concrete Example:
In a chemistry corpus, random masking might hide the word 'process' (common in all domains), which is less informative for learning chemistry. Difference-Masking identifies that 'molecule' is unique to the chemistry domain compared to general web text and prioritizes masking it to force the model to learn chemical concepts.
Key Novelty
Difference-Masking (TF-ICF based masking)
- Identifies 'difference anchors': words that appear frequently in the target domain but infrequently in the general pretraining corpus (using a TF-IDF-like metric called TF-ICF).
- Generates a masking probability distribution where tokens are more likely to be masked if they are semantically similar to these difference anchors.
- Applies this strategy to both text (using token similarity) and video (using object detection labels) without requiring supervised task labels.
Architecture
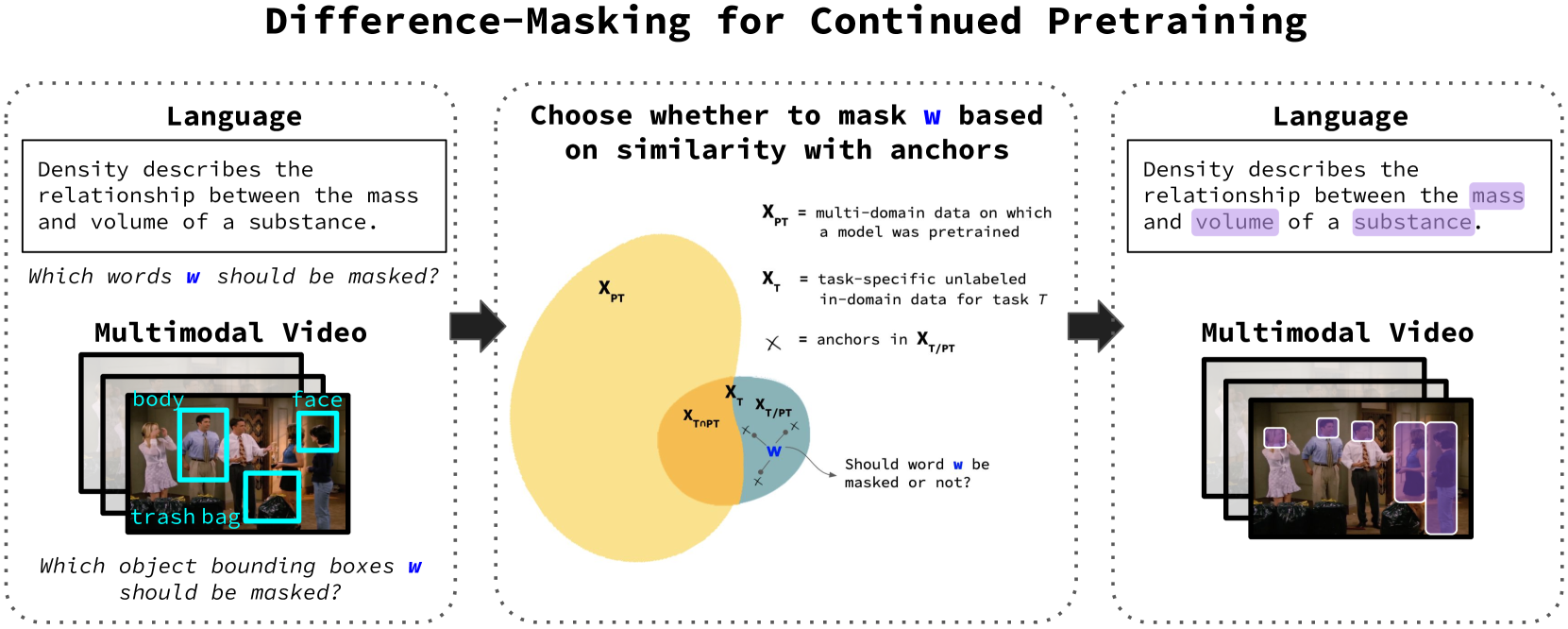
The Difference-Masking pipeline illustrating the two-step process: finding difference anchors and then masking based on similarity.
Evaluation Highlights
- Outperforms random masking and 5 other baselines across 4 datasets (ChemProt, ACL-ARC, TVQA, Social-IQ).
- +1.16% accuracy improvement on ChemProt over the strongest baseline (Salient Span Masking) using RoBERTa.
- +2.37% accuracy improvement on Social-IQ over Random Masking using MERLOT-Reserve.
Breakthrough Assessment
7/10
Simple, intuitive, and effective method that outperforms complex baselines (like gradient-based or attention-based masking) without needing supervision. Extends well to multimodal settings.
