📝 Paper Summary
LLM Pretraining Objectives
Reasoning Capabilities
Chain-of-Thought (CoT)
RLP integrates reasoning into the pretraining phase by rewarding the model for generating internal thoughts that improve the prediction of the next token compared to a no-thought baseline.
Core Problem
Standard next-token prediction pretraining forces models to reason linearly and implicitly, failing to encourage explicit, multi-step thinking or integration with world knowledge before output generation.
Why it matters:
- Current reasoning abilities are typically induced only during post-training (SFT, RLHF), limiting the model's fundamental grounding in logic during its primary learning phase.
- Human comprehension is non-linear and integrates priors in parallel; standard pretraining lacks mechanisms to mimic this, resulting in models that struggle with complex reasoning without heavy fine-tuning.
Concrete Example:
In standard training, a model predicts the answer to a math problem token-by-token immediately. If the problem requires intermediate steps (e.g., '15 * 12'), the model might guess '180' by rote memorization or fail. RLP forces it to generate '10*15=150, 2*15=30, 150+30=' as a thought before predicting '180', rewarding this thought if it makes '180' more probable.
Key Novelty
Reinforcement Learning Pre-training (RLP)
- Treats generating a Chain-of-Thought (CoT) as a latent action taken before predicting the next token, rewarding thoughts that increase the likelihood of the correct next token.
- Uses a 'no-think' baseline (an Exponential Moving Average of the model) to measure information gain, creating a dense, verifier-free reward signal applicable to any text document.
Architecture
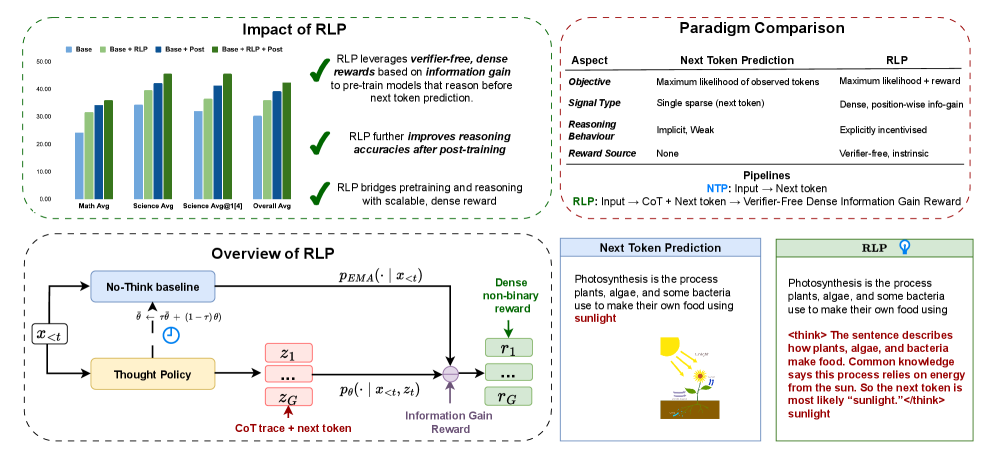
Illustration of the RLP training process compared to standard Next-Token Prediction.
Evaluation Highlights
- +19% average improvement on 8 math/science benchmarks for qwen3-1.7b-base pretrained with RLP compared to the standard base model.
- +35% relative improvement for Nemotron-Nano-12B-v2 on overall benchmarks using only 0.125% of the data compared to a heavily trained baseline.
- Gains persist after strong post-training (SFT + RLVR), with the RLP model outscoring the continuously pretrained baseline by 7% on average.
Breakthrough Assessment
9/10
Moves reasoning training from post-training to pretraining using a scalable, verifier-free objective. Demonstrates massive gains on base models that compound with further training.