📝 Paper Summary
Data Curation for LLMs
Web Crawling
Pretraining Data Filtering
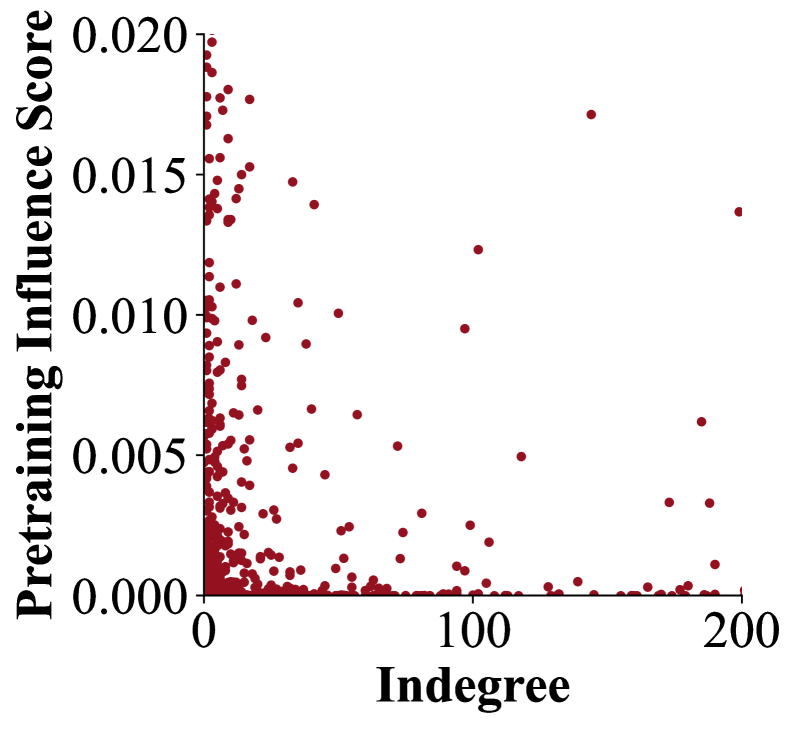
Craw4LLM improves pretraining data collection by prioritizing URLs based on their predicted influence on LLM quality rather than traditional graph connectivity metrics like PageRank.
Core Problem
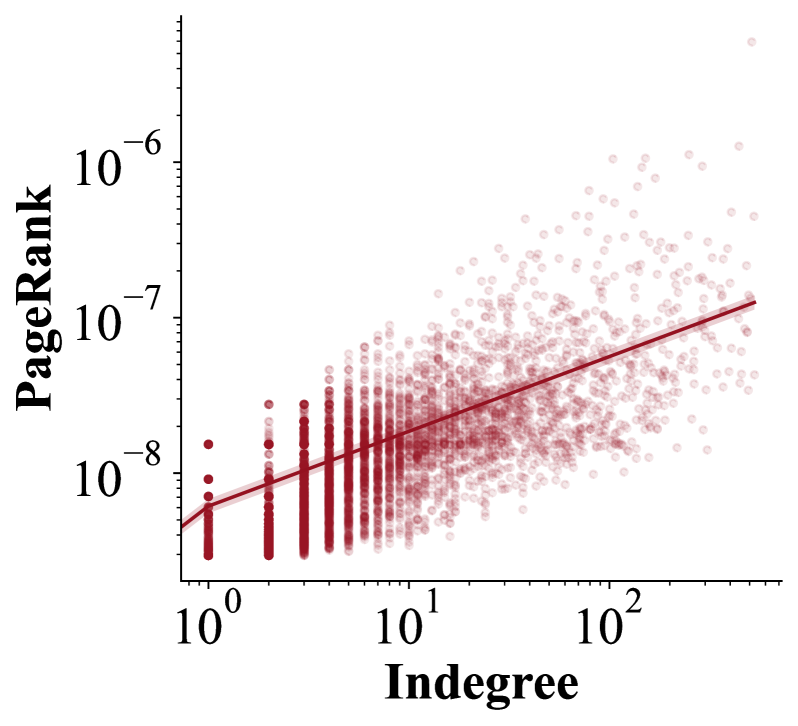
Traditional web crawlers prioritize pages with high connectivity (e.g., high indegree), which correlates poorly with the data quality needed for LLM pretraining, leading to over 90% of crawled data being discarded.
Why it matters:
- Inefficiency leads to massive waste of computational resources processing useless data
- Over-crawling burdens website operators with redundant traffic, raising ethical and legal concerns
- Current methods require crawling 4-5x the necessary data to find high-quality documents
Concrete Example:
A standard crawler might prioritize a link farm or directory page because it has many incoming links (high indegree), even though its text is low-quality spam. Craw4LLM would ignore it if the classifier predicts low educational value, instead following a link to a high-quality but less-connected blog post.
Key Novelty
LLM-Influence-Based Crawling Priority
- Replace standard graph-based priority signals (like PageRank or indegree) with a quality score derived from pretraining data filters (e.g., DCLM fastText or FineWeb-Edu classifiers)
- Score unvisited URLs based on the quality of their parent pages or direct scoring, prioritizing the exploration of the web graph towards high-quality 'neighborhoods' useful for LLMs
Architecture
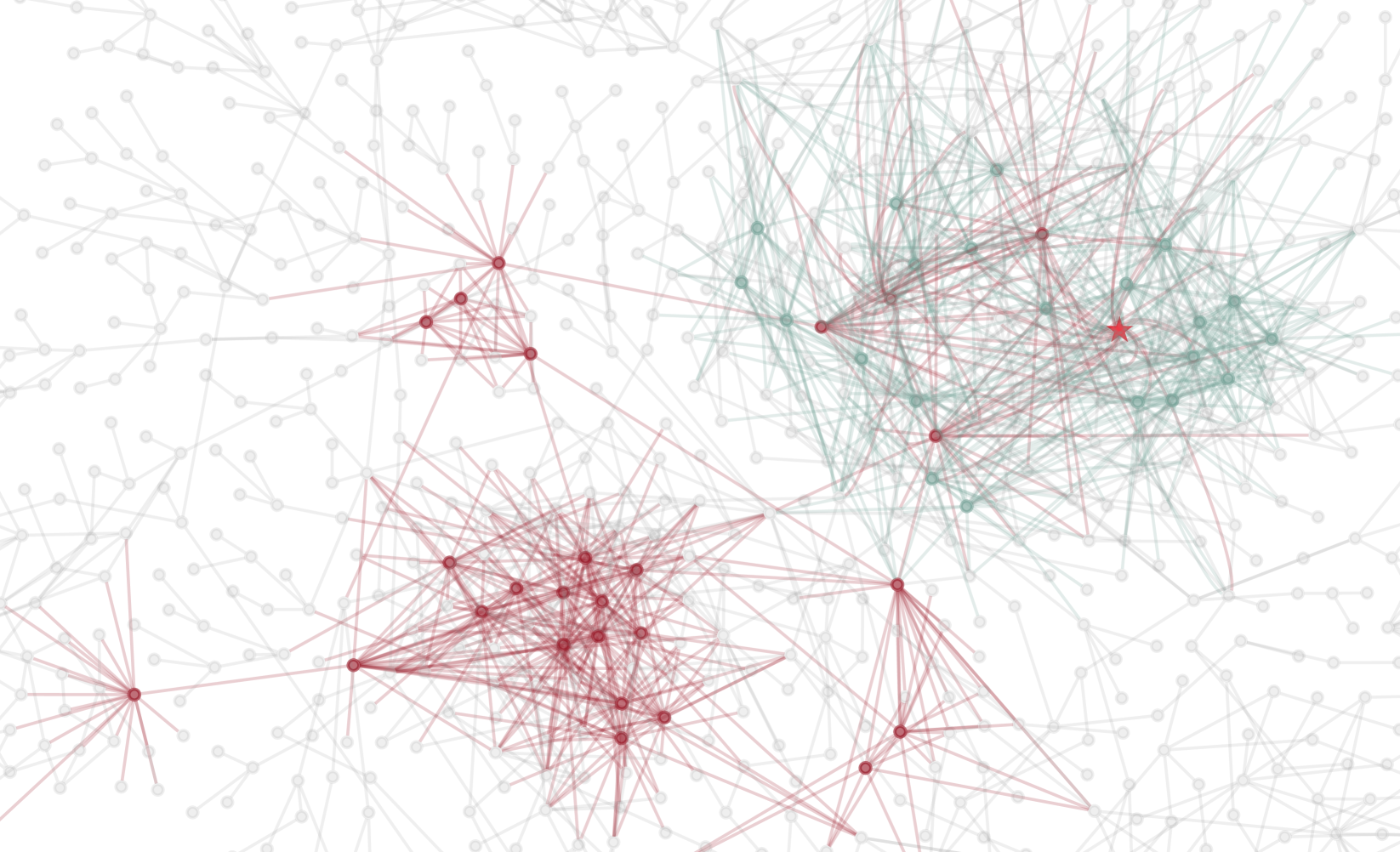
Conceptual workflow of Craw4LLM vs Traditional Crawlers
Evaluation Highlights
- Matches the downstream performance of traditional crawls while crawling only 21% of the total URLs
- Achieves >95% of the theoretical oracle performance (selecting from the full web graph) while crawling just 1x the target dataset size
- Outperforms traditional crawlers that collect 2x or 4x the data followed by filtering, validating that quality-first crawling is more efficient than crawl-then-select
Breakthrough Assessment
7/10
Simple but highly effective shift in crawling paradigm. Directly addresses the massive inefficiency of current data pipelines. Simulation-based validation is a limitation, but the efficiency gains are substantial.