📝 Paper Summary
Transfer Learning
Supervised Pre-training
Label Space Design
Fine-grained pre-training improves downstream performance on coarse tasks by forcing models to learn rare features that are otherwise ignored due to simplicity bias during coarse-grained training.
Core Problem
Neural networks tend to learn only the most common, simple features ('simplicity bias') when trained on coarse labels, failing to learn fine-grained features necessary for recognizing hard samples.
Why it matters:
- Large-scale pre-training (e.g., ImageNet21k) is standard, but the specific impact of label hierarchy choice is under-explored
- Training on massive datasets with overly coarse labels may waste data potential by not incentivizing the model to learn rich feature representations
- Understanding this helps optimize data labeling strategies for foundation models
Concrete Example:
In a 'cat vs dog' task, a model might only learn common ear shapes (shortcut), failing on a rare 'Persian cat' where those shapes are obscured; fine-grained 'breed' labels force the model to learn breed-specific textures, fixing this.
Key Novelty
Granularity-Generalization Correspondence
- Theoretically proves that coarse training only learns 'common' features, while fine-grained training forces the learning of 'rare' features
- Demonstrates that pre-training label granularity must align with the target task's underlying feature hierarchy to be effective
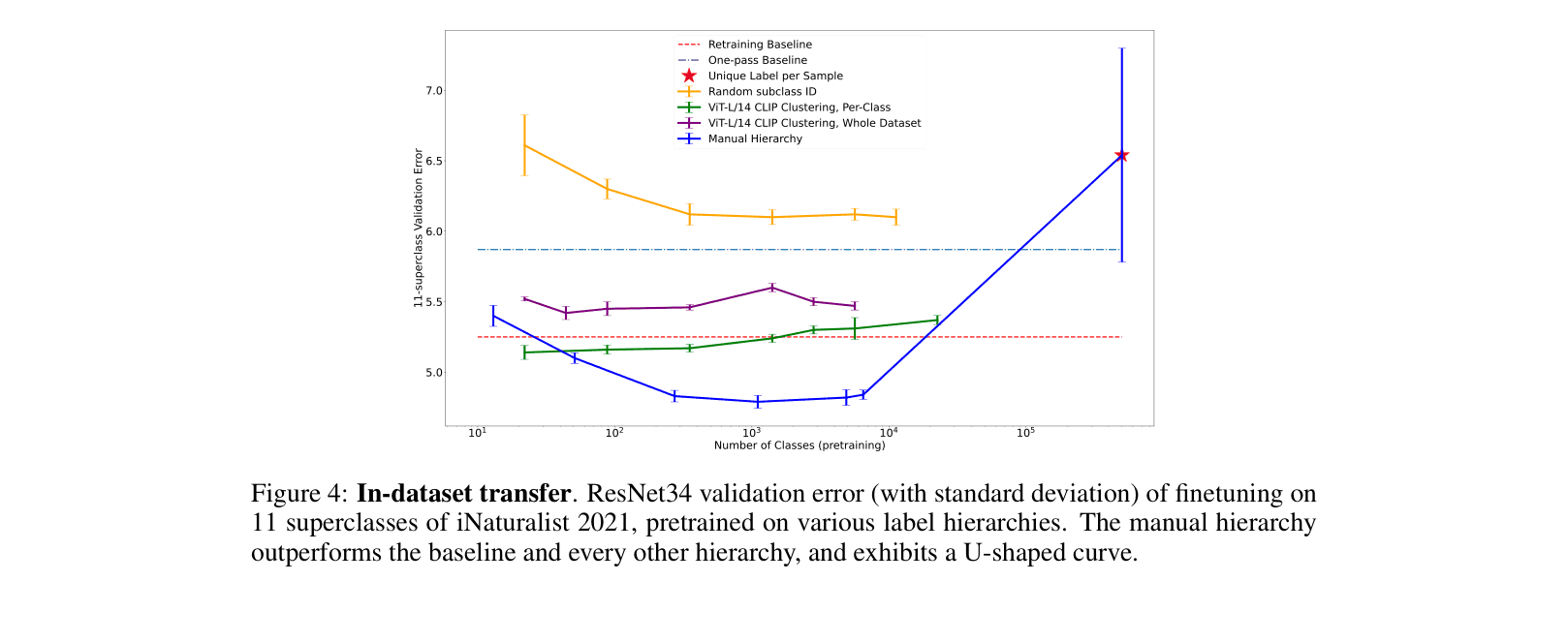
- Identifies a 'U-shaped' performance curve: extremely fine labels (e.g., unique ID per sample) hurt performance, as do overly coarse labels
Architecture

Theoretical data model illustrating 'common' vs 'fine-grained' features in image patches
Evaluation Highlights
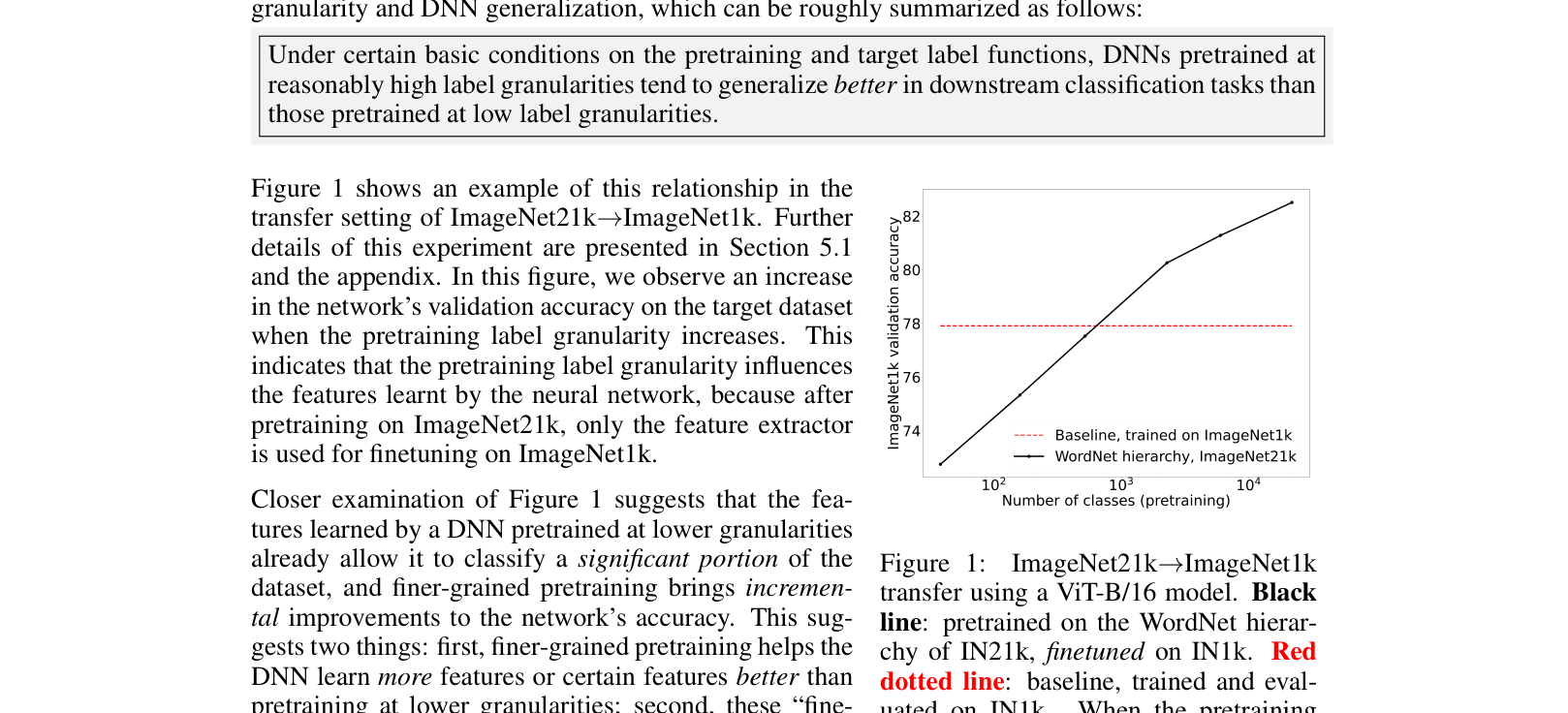
- Pre-training on ImageNet21k leaf labels (level 0) achieves 82.51% accuracy on ImageNet1k, significantly outperforming the 77.91% baseline
- Pre-training on coarser ImageNet21k levels (e.g., level 9) degrades performance to 72.75%, worse than training from scratch
- Manual hierarchies consistently outperform clustering-based or random label hierarchies for transfer learning on iNaturalist 2021
Breakthrough Assessment
7/10
Provides strong empirical and theoretical backing for the intuition that 'finer labels are better,' while adding nuance about alignment and the limits of granularity.