📝 Paper Summary
Neural PDE Solvers
Transfer Learning for Scientific Machine Learning
Operator Learning
PreLowD pretrains neural operators on inexpensive 1D PDE data and transfers the learned weights to solve 2D PDEs, significantly reducing error compared to training from scratch.
Core Problem
Training neural PDE solvers for high-dimensional systems requires expensive simulated data (scaling as O(N^6) in 2D), making large-scale pretraining computationally prohibitive.
Why it matters:
- Data generation for high-dimensional PDEs is extremely costly compared to 1D systems
- Standard pretraining requires massive datasets that match the downstream dimensionality
- Existing transfer learning methods focus on different coefficients or physics within the same dimension, missing the opportunity to leverage cheaper lower-dimensional data
Concrete Example:
Solving a 2D diffusion equation traditionally requires costly O(N^6) implicit solver steps for data generation. A model trained from scratch on limited 2D data underfits, failing to capture dynamics that could have been learned cheaply from abundant O(N^3) 1D diffusion data.
Key Novelty
Cross-Dimensional Pretraining (PreLowD)
- Train a factorized neural operator (FFNO) on cheap 1D PDE data, then transfer the learned Fourier weights to a 2D model
- Exploits the mathematical similarity of differential operators (like gradients and Laplacians) across dimensions
- Since FFNO parameters are defined per-axis, 1D weights can be directly reused to initialize both x and y axes in 2D models
Architecture
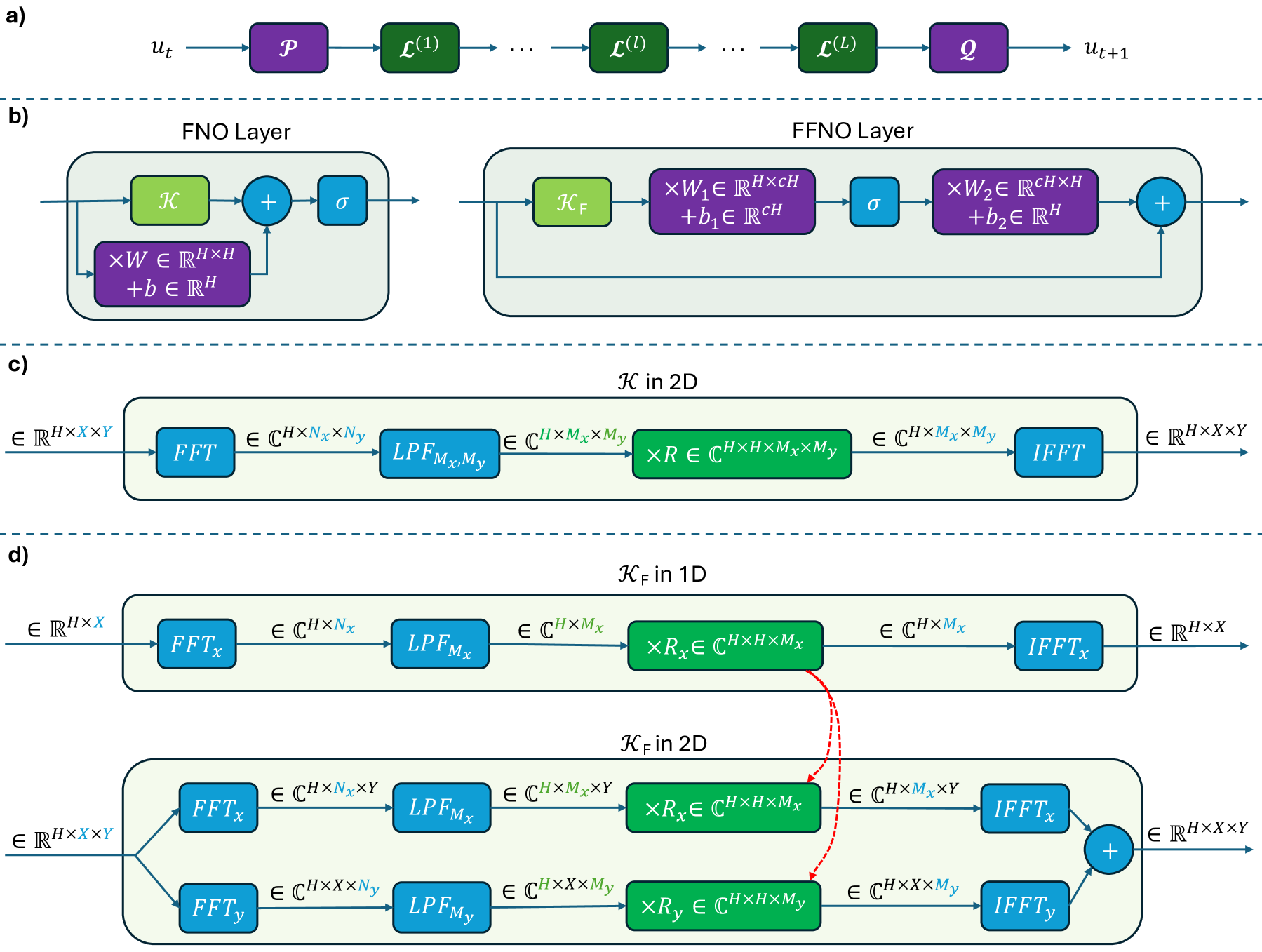
Overview of FNO and FFNO architectures, illustrating the factorized kernel integral operator that enables weight sharing.
Evaluation Highlights
- Reduces average relative error by ~50% on 2D diffusion equation compared to random initialization (5-step rollout)
- Performance gains amplify over longer rollout horizons and for systems with higher diffusion coefficients
- Achieves lower error with fewer 2D training samples, demonstrating improved data efficiency
Breakthrough Assessment
7/10
A clever, mathematically grounded efficiency hack for scientific ML. While currently demonstrated on simple PDEs (Advection/Diffusion), it addresses a major bottleneck (data cost) in a novel way via dimensional transfer.