📝 Paper Summary
Reinforcement Learning for Pretraining
Active Learning
PretrainZero applies reinforcement learning directly to general pretraining data by actively generating and predicting masked spans, enabling reasoning capabilities to emerge without supervised fine-tuning or external reward models.
Core Problem
Applying reinforcement learning (RL) to general pretraining is difficult because standard methods rely on verifiable rewards (like math answers) which are scarce in general corpora, or inefficient fixed masking strategies.
Why it matters:
- Post-training RL (like RLHF) hits a 'data-wall' due to reliance on expensive human labels or domain-specific verifiers
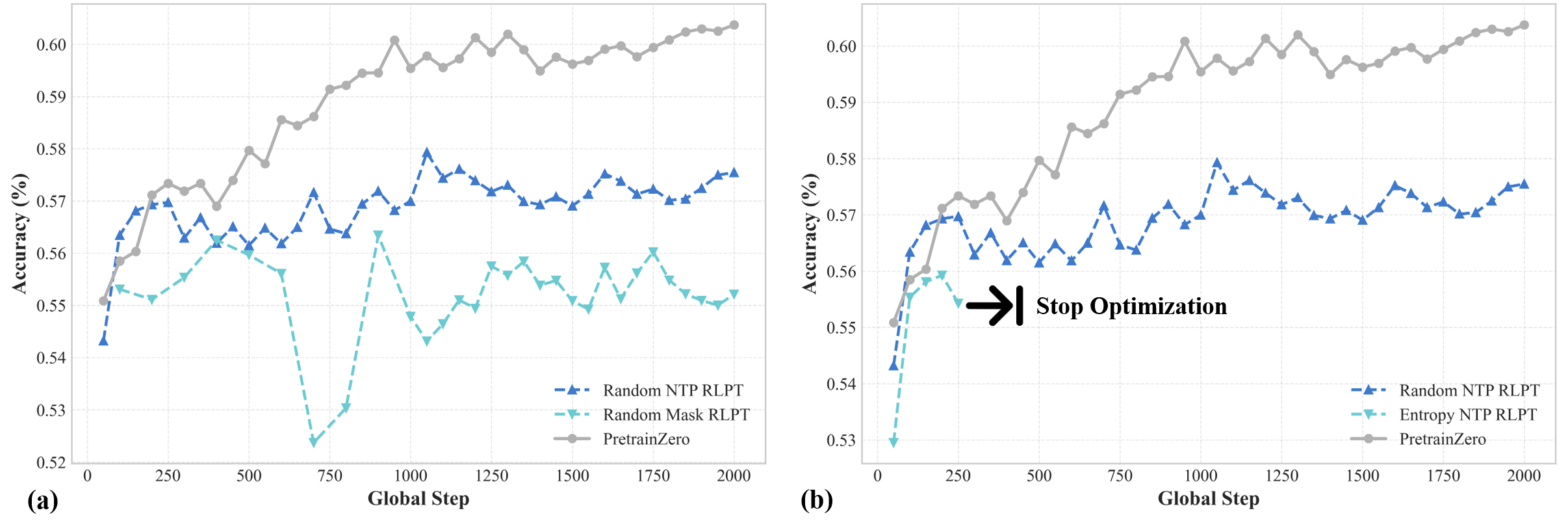
- Existing reinforcement pretraining attempts fail on real-world noisy data because random or entropy-based token selection creates unstable or trivial learning signals
- Standard self-supervised learning (next-token prediction) captures patterns but does not explicitly incentivize the reasoning chains seen in expert models
Concrete Example:
When using entropy-based masking on noisy Wikipedia data, the model might select a high-entropy token that is simply noise or formatting rather than a reasoning target. This causes 'training collapse' where rewards degrade to zero because the target is unpredictable, unlike in clean synthetic datasets where high entropy correlates with difficulty.
Key Novelty
Reinforcement Active Pretraining
- Mimics human active learning by training a 'mask generator' policy to actively find informative, learnable spans within the data, rather than using random masking
- Simultaneously trains a 'reasoner' policy to recover these masked spans via Chain-of-Thought, using exact-match with the original text as a ground-truth verifier
- Formulates this as a min-max game where the generator tries to create challenging masks (lowering prediction accuracy) while the reasoner tries to solve them
Architecture
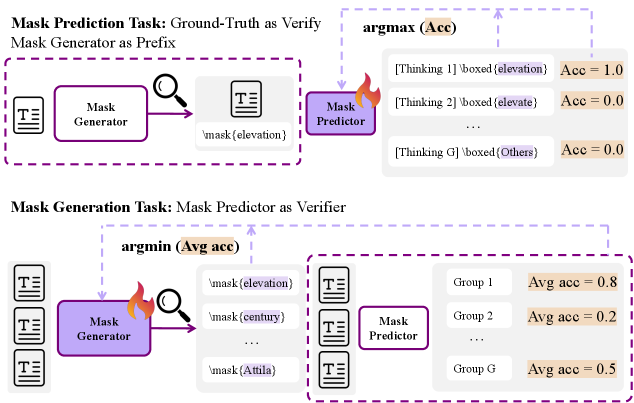
The Reinforcement Active Pretraining framework showing the interaction between Mask Generation and Mask Prediction.
Evaluation Highlights
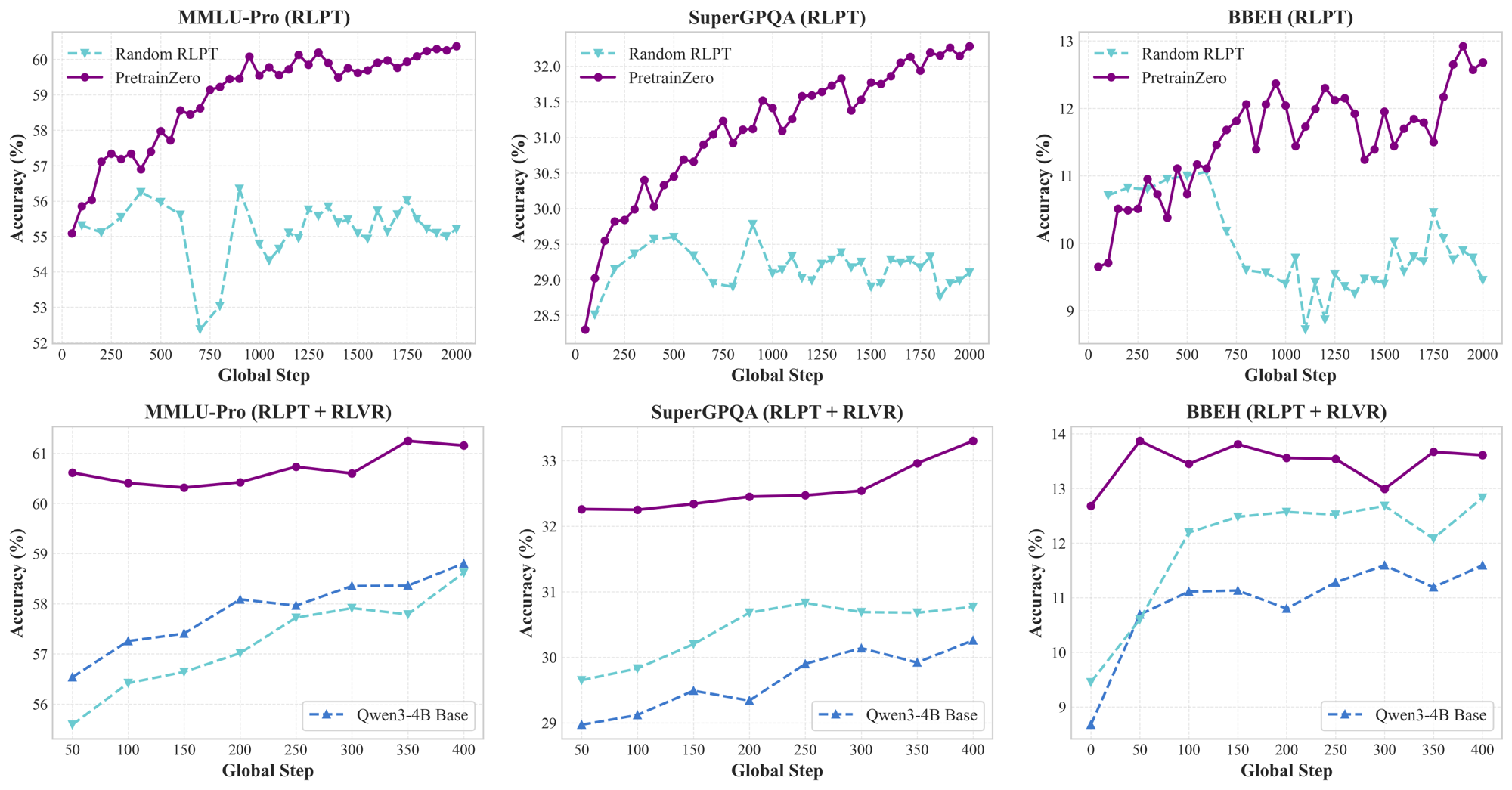
- +10.60 average improvement on math benchmarks for Qwen3-4B-Base after reinforcement pretraining, without any SFT data
- +8.43 improvement on MMLU-Pro for Qwen3-4B-Base, demonstrating generalization to complex reasoning beyond simple completion
- +3.04 improvement on SuperGPQA after post-training, showing that the pretrained reasoning capabilities transfer to downstream RLVR tasks
Breakthrough Assessment
8/10
Significant step in removing the reliance on SFT and external reward models for reasoning. Successfully applies RLVR-style learning to raw pretraining data via active learning, showing strong empirical gains.