📝 Paper Summary
Uncertainty Quantification (UQ)
Zero-shot Transfer
Large-Scale Pretraining
This paper introduces pretrained, feed-forward uncertainty modules for vision models that resolve gradient conflicts in loss prediction, scale to ImageNet-21k, and transfer zero-shot to unseen datasets as disentangled aleatoric uncertainty.
Core Problem
Accurate uncertainty estimation typically requires training on each specific task, and existing methods often interfere with the primary model's optimization or are computationally too expensive to scale.
Why it matters:
- Uncertainty is critical for trustworthy ML (e.g., deferring predictions), but adoption is low due to implementation complexity and inference costs.
- Existing 'loss prediction' methods suffer from gradient conflicts where the uncertainty objective degrades the main classification backbone.
- Current scalable methods are often task-specific, lacking a 'download and forget' solution that ships uncertainty with pretrained models.
Concrete Example:
In standard loss prediction, gradients from the uncertainty head negatively interact with the classification task, forcing early stopping (e.g., at epoch 12) and preventing large-scale pretraining convergence.
Key Novelty
Enhanced Loss Prediction with Stop-gradients and Caching
- Resolves gradient conflicts by adding a stop-gradient between the uncertainty head and the backbone, ensuring non-interference with the primary task.
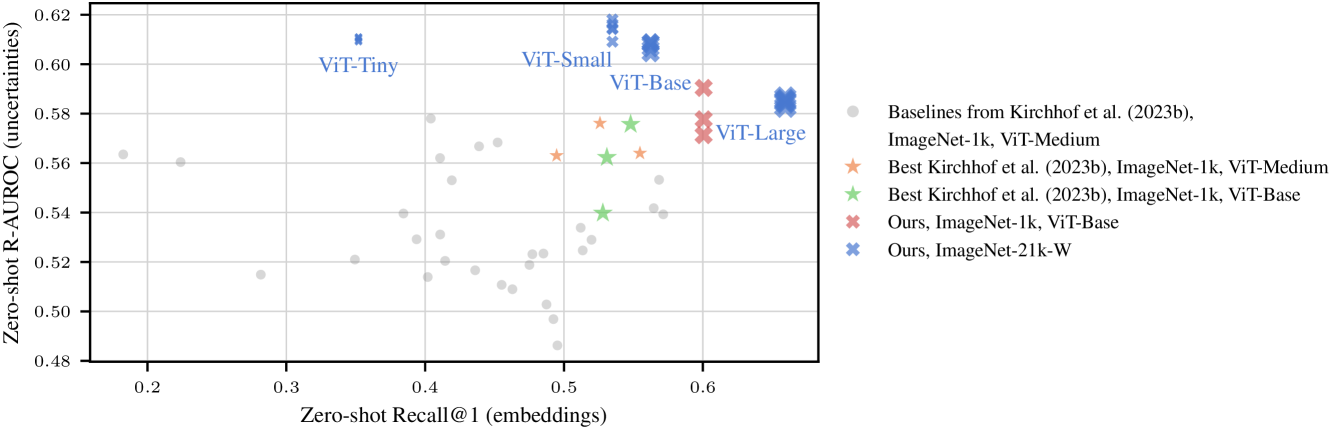
- Uses a caching mechanism for representations (frozen backbone) to accelerate uncertainty training by 180x, enabling scaling to ImageNet-21k-W.
- Adopts a ranking-based objective to make uncertainties scale-free and transferable across different downstream loss magnitudes.
Architecture
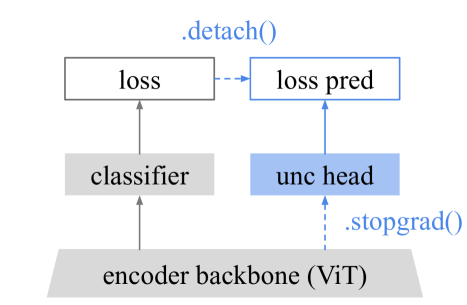
Comparison of Standard Loss Prediction vs. Enhanced Loss Prediction (Proposed). Shows gradient flows and training dynamics.
Evaluation Highlights
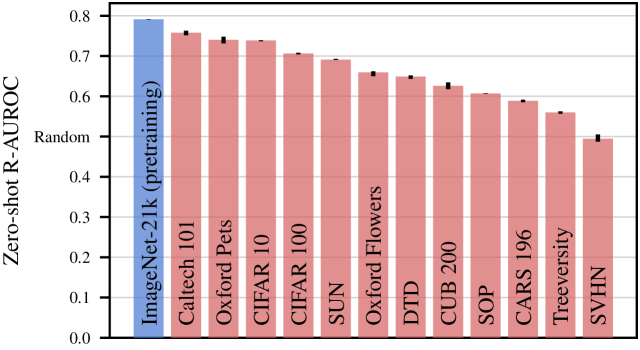
- Zero-shot uncertainty transfer (R-AUROC) on Caltech101 reaches 0.758, close to the pretraining dataset performance of 0.791.
- Training acceleration of up to 180x compared to standard loss prediction, reducing training time from 18 days to 2.5 hours on a single GPU for ViT-Large.
- Interventional experiments confirm uncertainties capture aleatoric uncertainty (AUROC 0.701 vs. human ambiguity labels) while remaining invariant to epistemic uncertainty.
Breakthrough Assessment
8/10
Significant practical contribution by enabling 'downloadable' uncertainty for ViTs. Solves the gradient conflict in loss prediction and provides strong evidence for zero-shot aleatoric uncertainty transfer.