📝 Paper Summary
Neural Operators
Scientific Machine Learning (SciML)
Pretraining strategies
This work conducts a systematic, model-agnostic comparison of vision-inspired and physics-based pretraining strategies for neural operators, finding that data augmentation and physics-aware tasks consistently improve generalization.
Core Problem
Neural operators often struggle to generalize to unseen physics and require large datasets, yet existing pretraining studies use tailored, incompatible architectures that prevent fair comparison of pretraining methods.
Why it matters:
- Current PDE pretraining is fragmented; tailored architectures make it impossible to isolate the effect of the pretraining strategy itself from the model design
- Training neural operators from scratch is slow and data-hungry; effective pretraining could enable few-shot learning in engineering contexts where data is scarce
Concrete Example:
A neural operator trained only on simple diffusion equations fails when tested on the Burgers equation with different coefficients. Current approaches fix this by designing a specific 'Burgers-Architecture,' whereas this paper seeks a general pretraining task (like 'Jigsaw' or 'Masking') that improves performance on *any* operator backbone.
Key Novelty
Systematic Benchmarking of Vision-Adapted Pretraining for PDEs
- Adapts computer vision pretraining tasks (e.g., Jigsaw puzzles, Masked Autoencoding) to the physics domain by treating PDE solutions as spatio-temporal videos
- Proposes physics-specific pretraining tasks like 'Derivative' (predicting spatial/temporal derivatives) and 'Coefficient' (regressing equation parameters) to learn dynamics
- Evaluates these strategies across multiple standard backbones (FNO, UNet, Transformer) to decouple strategy effectiveness from architecture scaling
Architecture

A conceptual diagram of the proposed pretraining strategies. It illustrates the different self-supervised tasks used to train the neural operator before fine-tuning.
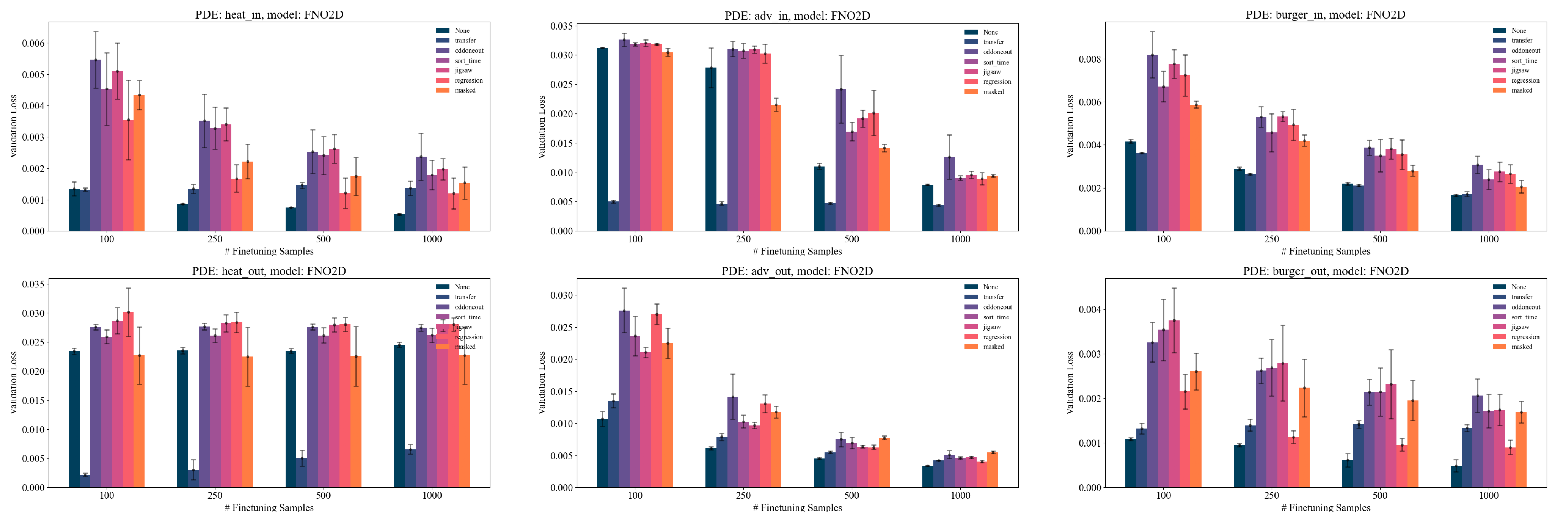
Evaluation Highlights
- Pretraining with Jigsaw or Masked strategies improves FNO performance by ~15-20% on downstream tasks compared to training from scratch
- Physics-agnostic data augmentations (Noise, Scale) consistently improve pretraining performance across all tested models and datasets
- In low-data regimes (10% training data), pretrained models significantly outperform scratch models, showing strong few-shot generalization capabilities
Breakthrough Assessment
7/10
Provides a much-needed rigorous empirical comparison of pretraining methods for PDEs, moving the field away from ad-hoc architectural solutions toward generalizable learning strategies.