📝 Paper Summary
Hallucination suppression
Uncertainty Estimation
HaluNet is a lightweight neural framework that detects hallucinations in single-pass LLM generation by fusing token probabilities, predictive entropy, and hidden semantic embeddings.
Core Problem
Existing hallucination detection methods either rely on expensive sampling-based consistency checks or capture only single types of uncertainty (probabilistic or semantic), missing the complementary signals needed for robust detection.
Why it matters:
- LLM hallucinations in Question Answering compromise reliability in search engines and autonomous agents
- Sampling-based methods (like SelfCheckGPT) are too computationally costly for real-time deployment
- Human annotation for hallucination labels is expensive and hard to scale, limiting the training of supervised detectors
Concrete Example:
A model might generate a confident-sounding but factually wrong answer. A probability-based detector might miss this if token likelihoods are high (due to fluency), while a semantic method might catch it via embedding anomalies. HaluNet combines both signals to detect the error where single-feature methods fail.
Key Novelty
HaluNet: Multi-Granular Uncertainty Fusion
- Unifies three distinct uncertainty signals—token log-likelihoods (confidence), predictive entropy (distributional uncertainty), and hidden states (semantic trajectory)—into a single trainable network
- Uses a multi-branch architecture where scalar features are processed by MLPs and embeddings by CNNs, fused via attention or concatenation
- Trains on 'pseudo-gold' labels generated by an LLM-as-a-Judge, eliminating the need for expensive human annotation while enabling supervised learning
Architecture
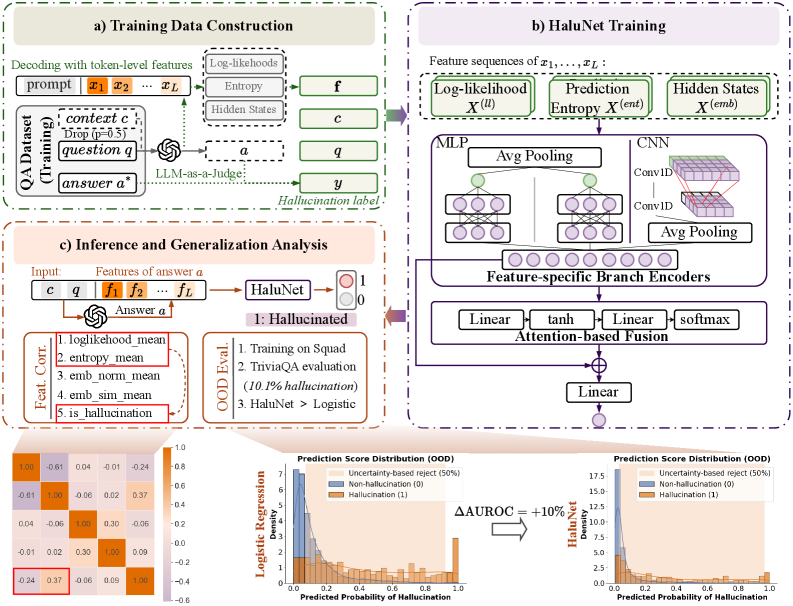
The architecture of HaluNet showing how token-level features are processed and fused.
Evaluation Highlights
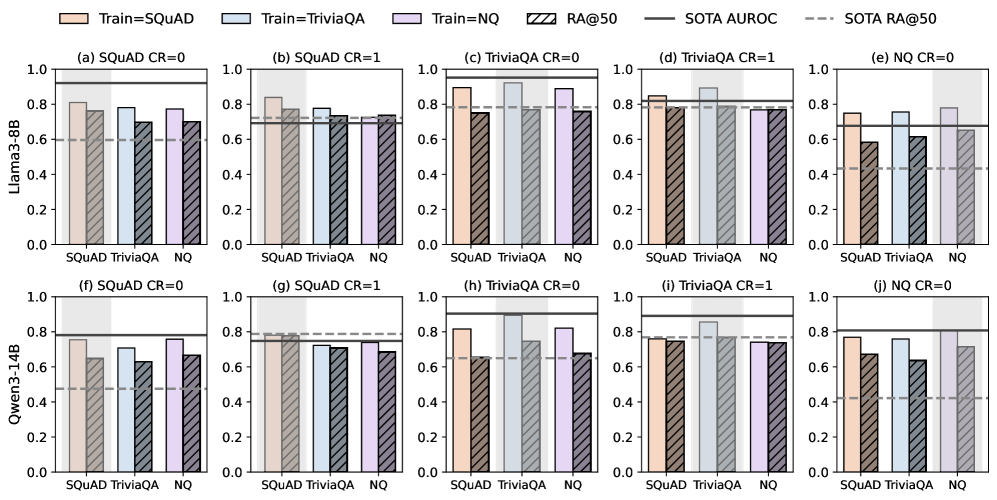
- Outperforms the strongest non-trained baseline by +6.7% AUROC on SQuAD (Llama3-8B)
- Achieves 0.893 AUROC on TriviaQA with Llama3-8B, a +6.6% improvement over baselines
- Maintains sub-second inference speed (single-pass), whereas sampling-based baselines like SelfCheckGPT are orders of magnitude slower
Breakthrough Assessment
7/10
Strong practical contribution uniting disparate uncertainty signals into a lightweight, effective framework. While the components (entropy, embeddings) are known, the fusion architecture and supervision strategy yield SOTA efficiency-accuracy balance.