📝 Paper Summary
Task-Adaptive Pretraining (TAP)
Multi-Level Optimization (MLO)
Transfer Learning
TapWeight automatically optimizes the importance weights of multiple pretraining objectives by minimizing downstream validation loss through a three-level optimization framework using implicit differentiation.
Core Problem
Existing task-adaptive pretraining methods use multiple objectives (e.g., MLM, contrastive loss) but determining their relative importance requires expensive manual tuning or suboptimal equal weighting.
Why it matters:
- Domain discrepancies between general pretraining and downstream tasks lead to performance degradation if not adapted correctly
- Manual hyperparameter search becomes computationally prohibitive as the number of pretraining objectives increases (e.g., 5 objectives in Imagemol)
- Equal weighting disregards that certain objectives (like contrastive learning) may be far more beneficial for specific downstream tasks (like semantic similarity) than others
Concrete Example:
When adapting BERT for semantic textual similarity, a contrastive learning objective is more important than masked language modeling. Standard approaches might weight them equally (suboptimal) or require exhaustive grid search to find that contrastive loss should have a higher weight.
Key Novelty
Three-Level Optimization for Pretraining Weights
- Treats pretraining objective weights as learnable hyperparameters optimized against downstream validation performance
- Uses a nested three-stage loop: (1) pretrain with fixed weights, (2) finetune a proximal model on task data, (3) update weights based on validation loss
- Employes implicit differentiation to propagate gradients through the finetuning and pretraining steps back to the objective weights
Architecture
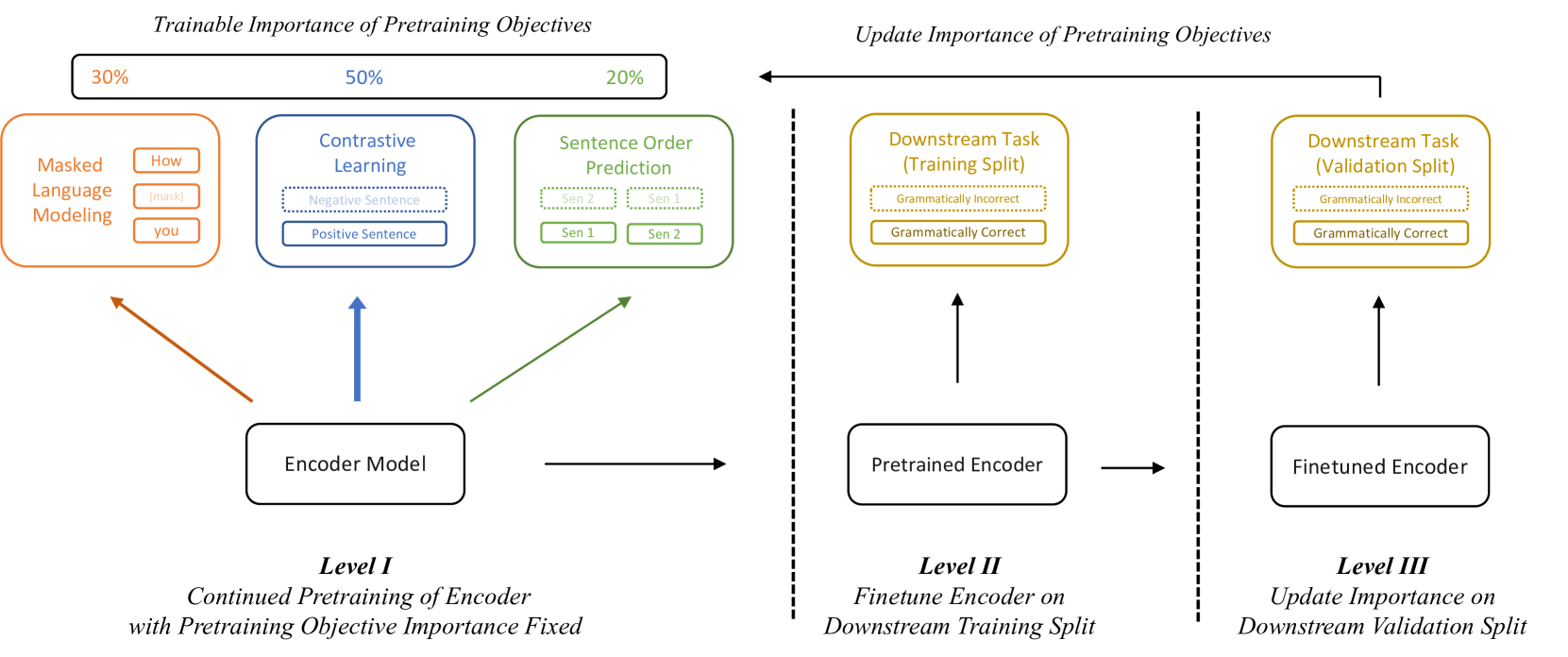
The complete framework of TapWeight showing the three-level optimization process
Breakthrough Assessment
7/10
Offers a mathematically rigorous solution to the 'magic number' problem in multi-objective pretraining. While the MLO technique is known, applying it to reweight pretraining objectives based on downstream feedback is a logical and useful advancement.