📝 Paper Summary
Sleep Staging
EEG Analysis
Synthetic Data Pretraining
FPT pretrains neural networks to predict the frequency content of synthetically generated random time series, enabling accurate sleep staging on small real-world datasets without requiring large empirical pretraining data.
Core Problem
Deep learning for sleep staging typically requires large, diverse datasets to generalize across subjects, but medical data is often scarce, expensive to label, and restricted by privacy concerns.
Why it matters:
- Acquiring large-scale EEG datasets is logistically difficult due to varying clinical protocols and strict ethical guidelines.
- Small datasets lead to overfitting, preventing deep neural networks from learning robust features necessary for reliable medical diagnostics.
- Current self-supervised methods still rely on large amounts of unlabeled empirical data, which may not always be available.
Concrete Example:
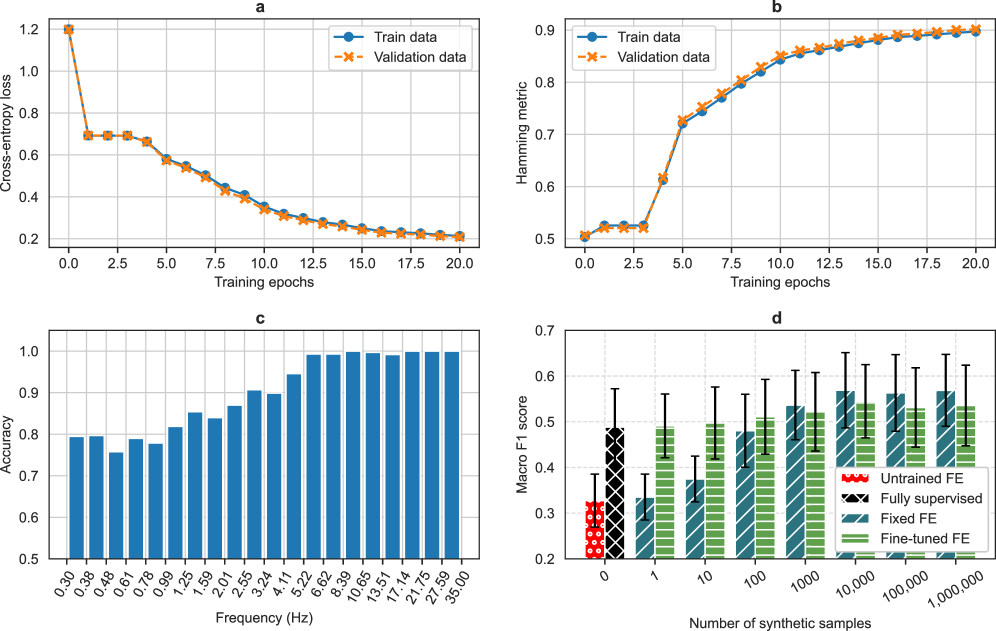
When fine-tuning on only 50 samples from a single subject, standard supervised models overfit and fail to generalize. FPT (Frequency Pretraining) leverages synthetic priors to achieve significantly higher accuracy in this low-data scenario.
Key Novelty
Frequency Pretraining (FPT)
- Generates synthetic time series solely by summing sine waves with random frequencies drawn from predefined bins, completely eliminating the need for real EEG data during pretraining.
- Trains a neural network to predict which frequency bins were used to generate the signal, forcing the model to learn frequency-discriminative features relevant for sleep staging.
Architecture
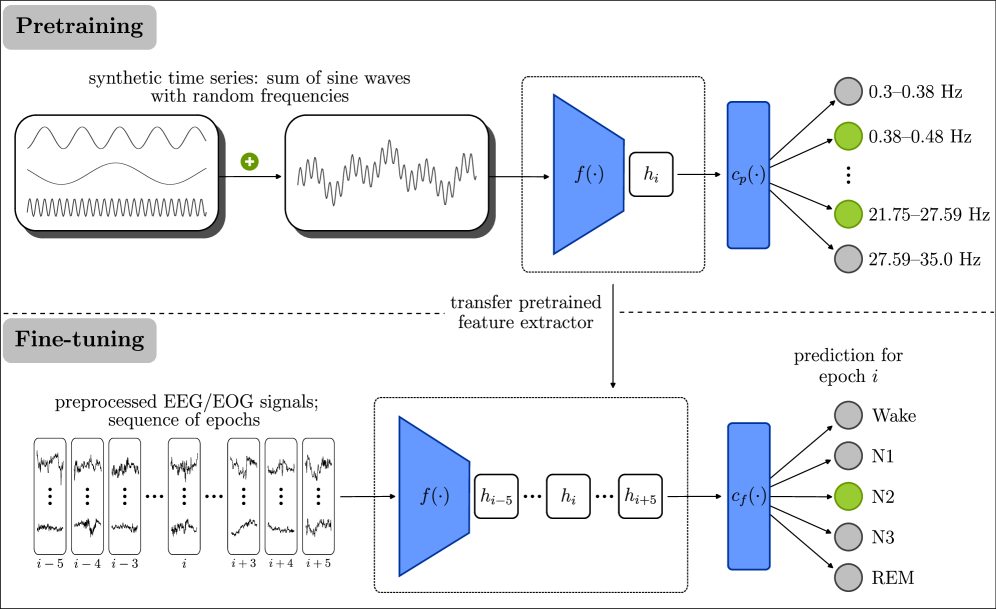
Illustration of the two-phase training process: (1) Pretraining on synthetic time series for frequency prediction, and (2) Fine-tuning on clinical sleep data for sleep staging.
Evaluation Highlights
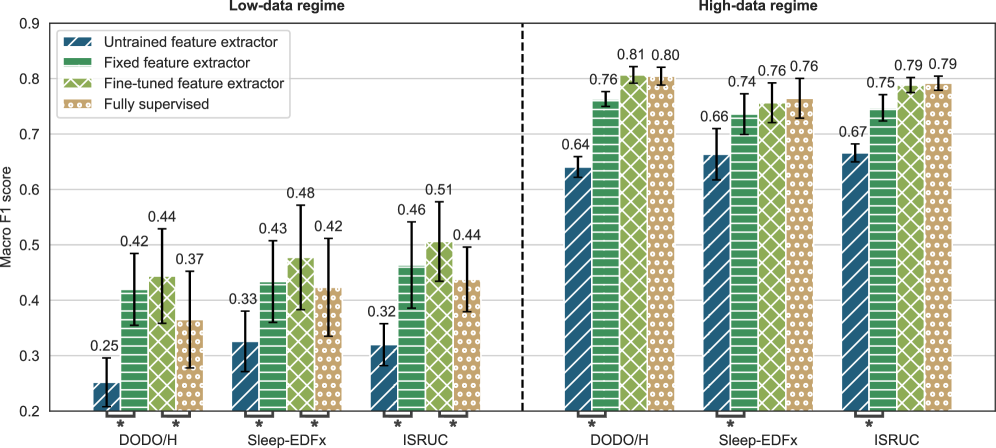
- Outperforms fully supervised baselines by 0.06–0.07 Macro-F1 in low-data regimes (50 samples) across three datasets.
- Matches performance of fully supervised methods (Macro-F1 0.76–0.81) when abundant data is available, confirming synthetic priors do not hinder capacity.
- Achieves comparable results to standard self-supervised methods (SimCLR, VICReg) trained on real EEG data, but without using any real data for pretraining.
Breakthrough Assessment
7/10
Strong proof-of-concept that synthetic data alone can replace large empirical datasets for pretraining in specific domains like EEG, offering a valuable tool for data-scarce medical applications.