📊 Experiments & Results
Evaluation Setup
Evaluation of reasoning transfer on OOD algorithmic tasks and controlled RL training experiments
Benchmarks:
- Esoteric Language Benchmark (Algorithmic reasoning (sorting, printing, math) in Brainf**k and Befunge) [New]
- Go 9x9 (Board game strategy)
Metrics:
- Accuracy (percentage of correct outputs)
- Win Rate (%)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Performance of state-of-the-art LLMs on the Esoteric Language Benchmark, showing poor generalization to novel syntaxes despite the tasks being algorithmically simple. | ||||
| Esoteric Language Benchmark (Brainf**k) | Average Accuracy | 0 | 12 | +12 |
| Esoteric Language Benchmark (Befunge) | Average Accuracy | 0 | 29 | +29 |
| Esoteric Language Benchmark (Brainf**k - Sorting) | Accuracy | 0 | 1.0 | +1.0 |
| Esoteric Language Benchmark (Befunge - Printing) | Accuracy | Not reported in the paper | 65.5 | Not reported in the paper |
| Controlled experiments on Go 9x9 comparing training paradigms: Supervised Pretraining (SPT) vs. Reward-based Pretraining (RPT) from scratch. | ||||
| Go 9x9 | Win Rate | 0 | 100 | +100 |
| Go 9x9 | Win Rate | 8 | 92 | +84 |
| Go 9x9 | Win Rate | 34 | 66 | +32 |
Experiment Figures
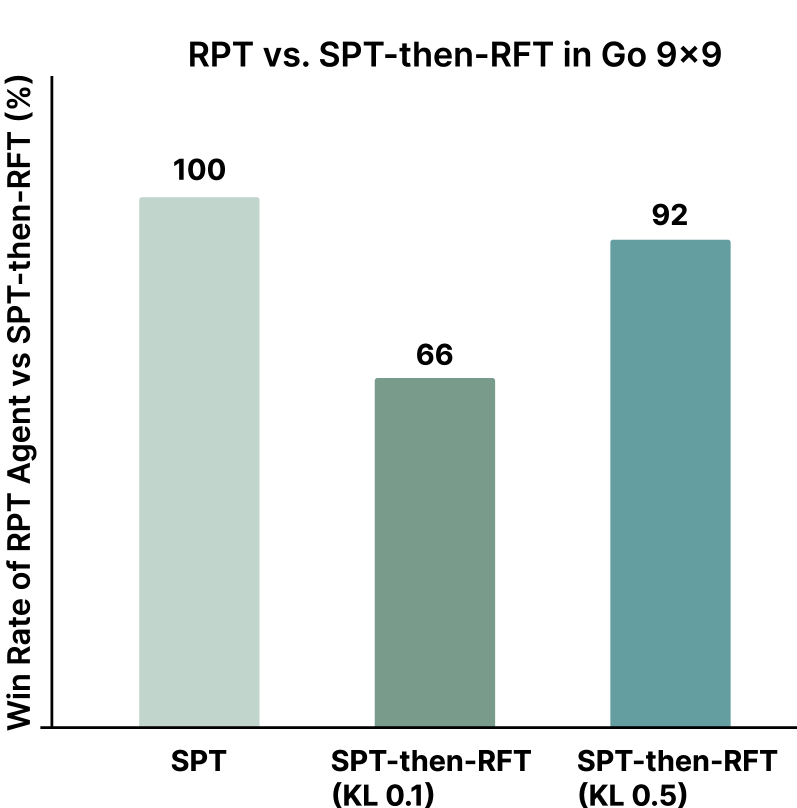
Win rates of Reward-based Pretraining (RPT) agents against various Supervised Pretraining (SPT) baselines in Go 9x9
Main Takeaways
- Current LLMs perform poorly on algorithmic tasks in esoteric languages (Brainf**k, Befunge) despite succeeding in Python, indicating a lack of true generalizable reasoning.
- In-context learning (10 examples) provides only marginal gains in Brainf**k (~4%), suggesting models cannot infer the underlying reasoning engine from few shots.
- Controlled Go experiments confirm that supervised pretraining on passive data (demonstrations) biases subsequent RL, preventing it from reaching the optimal performance achieved by RL from scratch.
- The 'o1' model, which uses RL post-training, performs best on the esoteric benchmark but still fails tasks like sorting, supporting the hypothesis that SPT limits the ceiling of reasoning capabilities.