📊 Experiments & Results
Evaluation Setup
Pretraining 1.46B parameter models on fixed token budgets and evaluating on downstream tasks
Benchmarks:
- Specific tasks not listed in snippet (Likely standard NLP tasks (reasoning, knowledge) following FineWeb-2 recipe)
Metrics:
- Aggregate Performance Score (implied from comparative results)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Aggregate Score (FineWeb-2 setup) | Score | 0.154 | 0.161 | +0.007 |
Experiment Figures
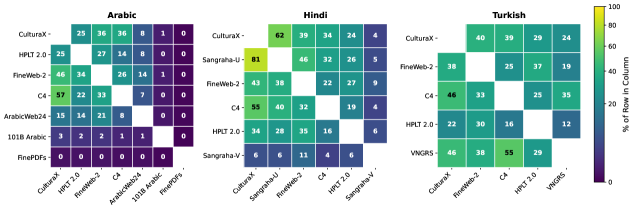
Pairwise token overlap between major Arabic web corpora (Venn diagram style implied)
Main Takeaways
- Cross-source agreement is a reliable signal of quality: content preserved by multiple independent pipelines generally yields better downstream model performance.
- The 'Matched' subset achieves competitive or superior performance to single-source baselines, often with less data or without complex filtering.
- The method is complementary to high-quality single-source curation: while cross-source agreement finds consensus quality, specialized pipelines (like ArabicWeb24) can still capture unique high-quality data.