📝 Paper Summary
Interpretability of Large Language Models
Chain-of-Thought (CoT) Reasoning
This paper proposes a framework using the Hopfieldian view to interpret Chain-of-Thought reasoning by modeling prompts as stimuli that activate latent concepts, enabling error localization and corrective control.
Core Problem
While Chain-of-Thought (CoT) significantly improves LLM reasoning, a rigorous explanation for *why* it works remains unclear, and existing interpretability methods (like saliency maps or neuron-level analysis) struggle to explain complex reasoning paths.
Why it matters:
- Current interpretability methods often require heavy human intervention or are limited to low-level neural activations, failing to capture high-level reasoning dynamics.
- Understanding CoT is crucial for identifying potential risks, localizing errors, and improving the faithfulness of LLM reasoning.
- There is a lack of frameworks that can both explain the inner workings of CoT and provide a mechanism to control or rectify reasoning errors.
Concrete Example:
In an arithmetic reasoning task (e.g., calculating distance between trains), LLaMA-2-7B might misinterpret 'distance covered by each train' as 'total distance'. Standard CoT simply produces the wrong answer. The proposed framework detects this via negative scores in the representation space and corrects it.
Key Novelty
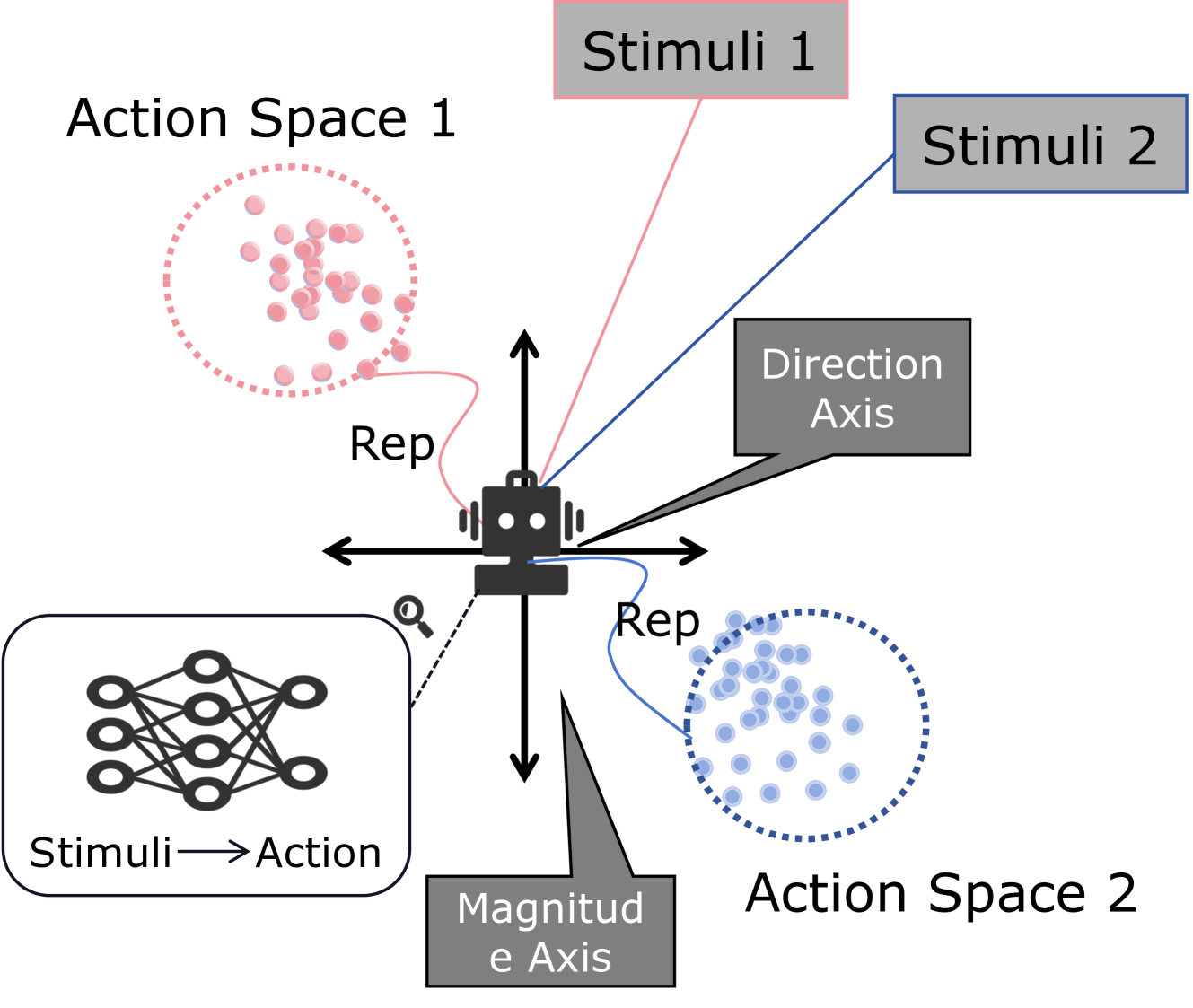
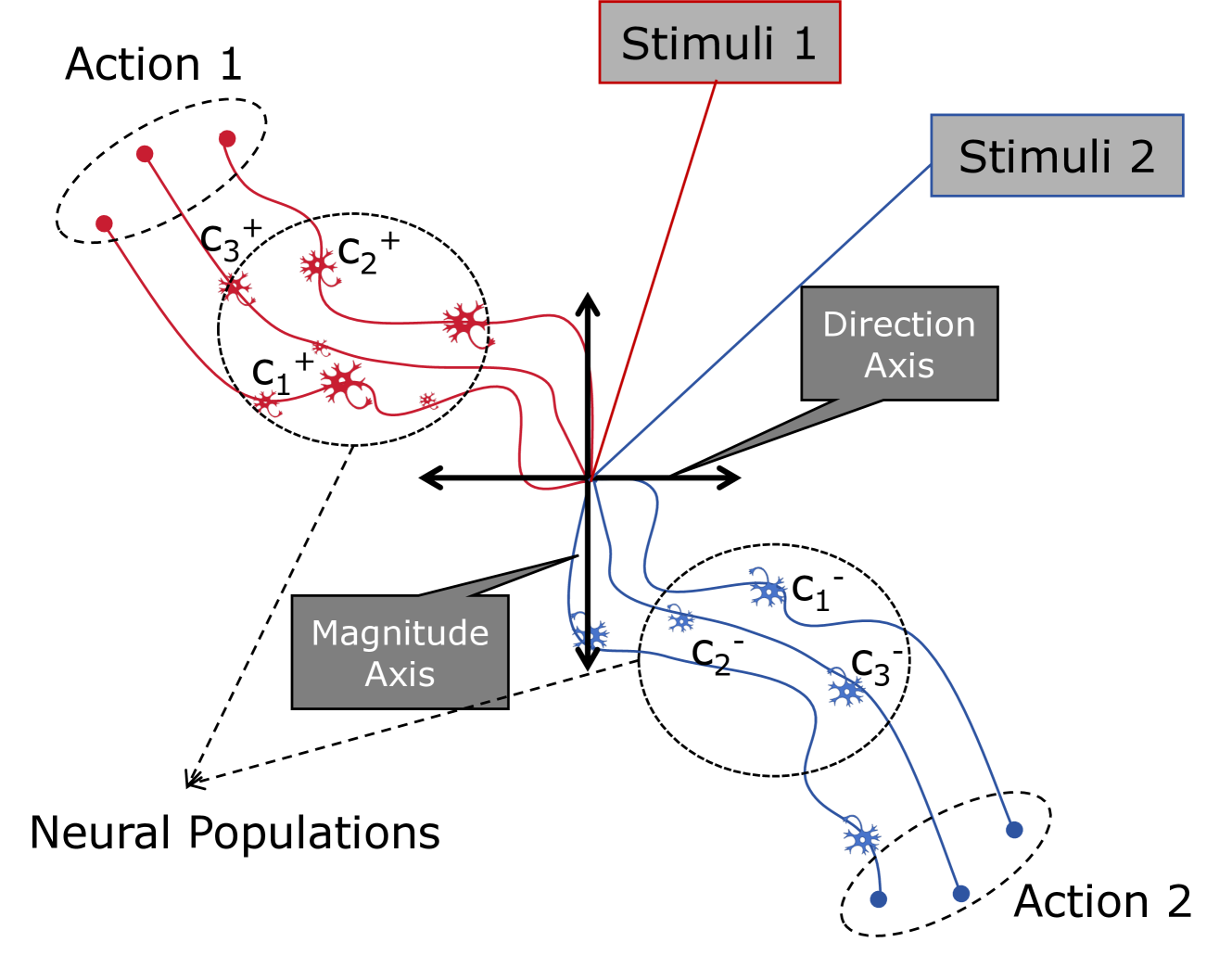
Hopfieldian Read-and-Control Framework for CoT
- Models LLM cognition as transformations in representational spaces triggered by stimuli (prompts like 'let's think step by step' or few-shot examples), analogous to the Hopfieldian view of the brain.
- Introduces a 'Read' operation to extract a 'reading vector' representing latent concepts activated by specific stimuli.
- Implements a 'Control' operation that injects this reading vector back into the model's representations to guide or correct the reasoning path during inference.
Architecture
The overall framework diagram showing the flow from Concept Modeling to Simulation, then Analysis (Read & Control).
Evaluation Highlights
- Achieved significant accuracy improvements on arithmetic tasks: +10.2% on MultiArith and +6.0% on GSM8K using LLaMA-2-7B-chat.
- Demonstrated effectiveness in commonsense reasoning, improving accuracy by 4.2% on CSQA and 3.6% on StrategyQA with LLaMA-2-13B-chat.
- Successfully applied to symbolic reasoning, gaining +8.4% on Last Letter Concatenation and +8.0% on Coin Flip tasks with LLaMA-2-7B-chat.
Breakthrough Assessment
7/10
Offers a novel theoretical lens (Hopfieldian view) for CoT interpretability and demonstrates practical utility through error localization and control. While performance gains are solid, it relies on known linear representation properties.