📝 Paper Summary
Autonomous Driving
Prompt Engineering
Multi-Modal Large Language Models (MLLMs)
PKRD-CoT is a zero-shot prompt framework that guides Multi-Modal Large Language Models through perception, knowledge, reasoning, and decision-making steps to improve autonomous driving performance without training.
Core Problem
Training end-to-end autonomous driving models is costly and complex, while standard data-driven approaches suffer from poor generalization and lack of interpretability.
Why it matters:
- Fine-tuning large MLLMs (Multi-Modal Large Language Models) requires substantial computational resources and data
- Existing data-driven driving models often struggle with long-tail scenarios (rare events) and lack the reasoning transparency of human drivers
- Generic prompting techniques fail to leverage the specific cognitive steps (perception, knowledge, reasoning) required for safe driving
Concrete Example:
In a scenario where a car should maintain speed, a standard zero-shot prompt might incorrectly advise stopping due to a lack of spatial reasoning, whereas PKRD-CoT correctly identifies the safe distance and decides to maintain speed.
Key Novelty
PKRD-CoT (Perception, Knowledge, Reasoning, and Decision-making Chain-of-Thought)
- Structured zero-shot prompt framework that forces the MLLM to mimic human driving cognition in four explicit steps
- Integrates a 'Memory' module within the prompt to store environmental context in structured JSON format, mitigating context loss in language models
- Uses a knowledge-driven approach to interpret traffic scenarios (e.g., red light -> stop) without requiring fine-tuning on driving datasets
Architecture
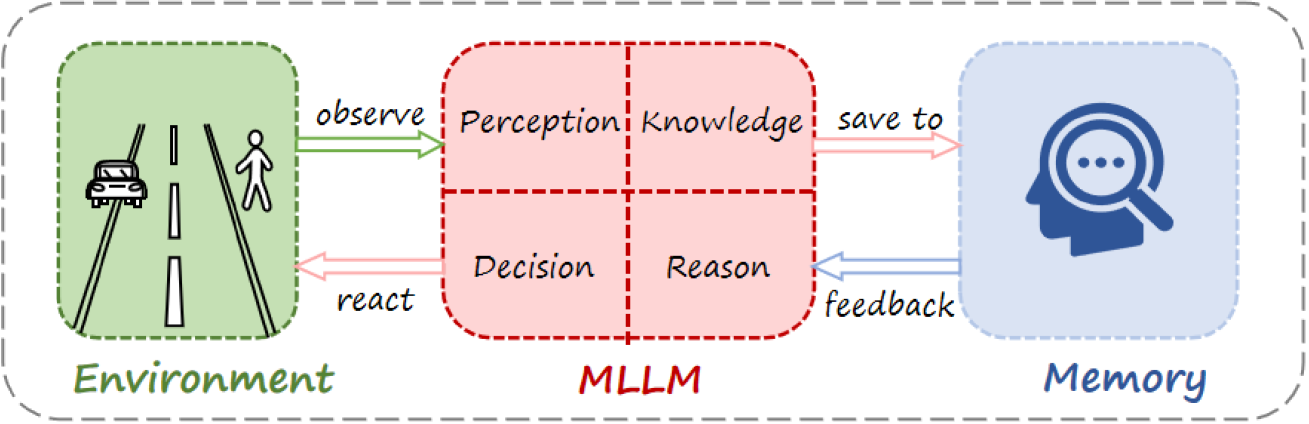
The PKRD-CoT framework structure mapping autonomous driving capabilities to prompt steps
Evaluation Highlights
- PKRD-CoT improves decision-making accuracy by 22% compared to standard zero-shot prompts in ablation studies
- GPT-4.0 achieves 100% accuracy in mathematical reasoning tasks (calculating vehicle distances) using the framework
- Claude and LLava1.6 achieve high average perceptual accuracies of 94% and 92% respectively on autonomous driving tasks
Breakthrough Assessment
7/10
A strong application of Chain-of-Thought to a specific domain (autonomous driving) with clear performance gains. While not a new model architecture, it effectively bridges MLLMs and control tasks via structured prompting.
