📝 Paper Summary
Chain-of-Thought Distillation
Curriculum Learning
Efficient Reasoning
KPOD improves Chain-of-Thought distillation by weighting tokens based on their significance to reasoning and scheduling training from easy (final steps) to hard (full rationale).
Core Problem
Standard CoT distillation treats all tokens equally and trains on full rationales simultaneously, ignoring that some tokens are irrelevant and that learning is more effective when progressing from easy to hard.
Why it matters:
- Irrelevant tokens (e.g., filler words) in rationales can distract student models, leading to reasoning errors if mimicked too closely
- Human cognitive learning progresses from easy to difficult tasks; forcing models to learn complex full rationales immediately is sub-optimal
- Deployment of massive LLMs (100B+ parameters) is resource-intensive; effective distillation to smaller models is critical for scalability
Concrete Example:
In the step 'Next, we just need to simply add up...: 30 + 80 = 110', words like 'simply' are irrelevant. A student model might prioritize mimicking 'simply' over the crucial calculation '30 + 80 = 110', leading to errors.
Key Novelty
Keypoint-based Progressive CoT Distillation (KPOD)
- Uses a mask learning module to identify 'keypoint' tokens (crucial for reasoning) versus irrelevant filler, assigning higher loss weights to keypoints during distillation
- Implements an 'in-rationale' progressive strategy: starts by training the student to generate only the final reasoning steps (easier), then gradually extends to the full rationale (harder)
- Dynamically selects diverse questions for difficulty escalation using a submodular maximization approach to prevent overfitting
Architecture
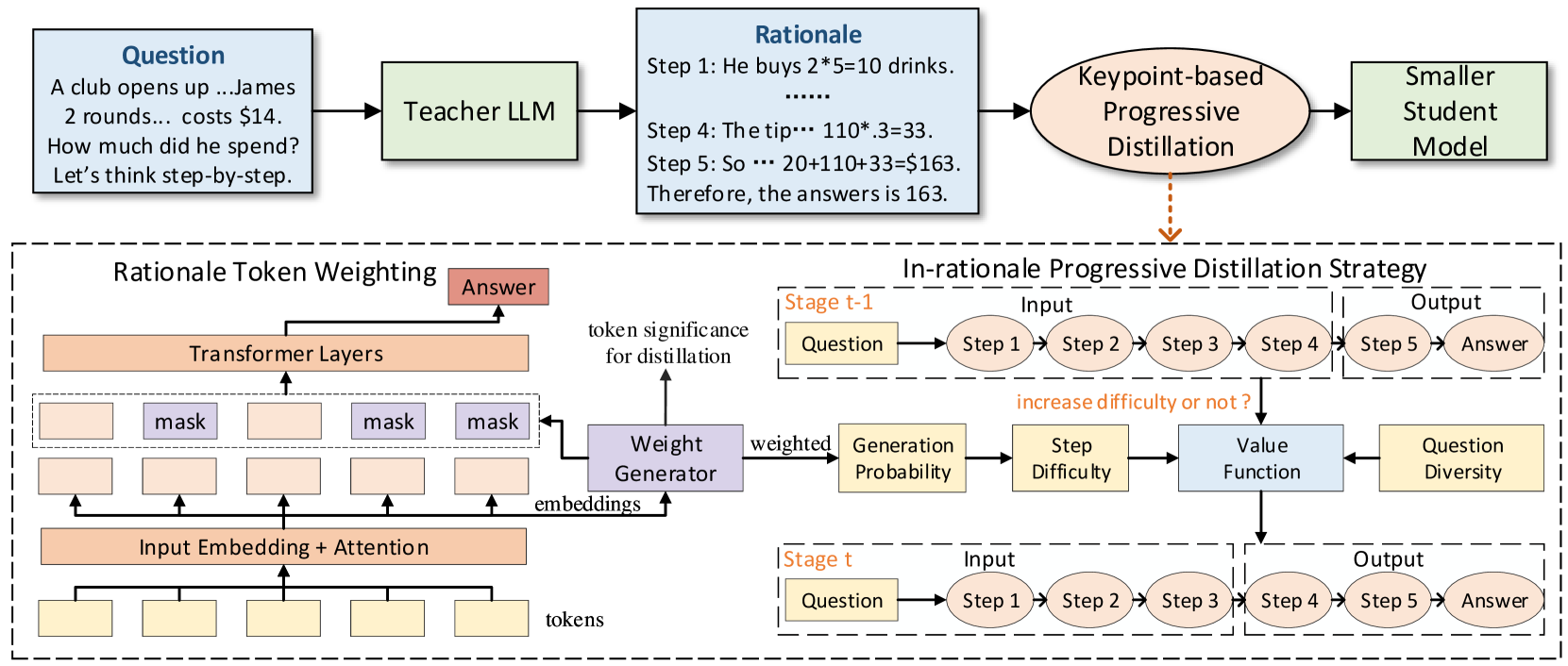
The overall framework of KPOD, showing the Teacher LLM generation, the Rationale Token Weighting Module, and the In-Rationale Progressive Distillation process.
Evaluation Highlights
- +3.45% average accuracy improvement over the best baseline (SCOTT) across four reasoning benchmarks using LLaMA-7B as the student
- Significantly outperforms standard Fine-tune CoT (+8.44% on average) and other distillation methods like MCC-KD and MT-CoT
- Achieves higher performance with fewer training samples compared to baselines, demonstrating data efficiency
Breakthrough Assessment
7/10
Solid methodological improvement combining token-level weighting (attention to detail) with curriculum learning (structure). Strong empirical gains, though the core concepts are evolutionary rather than revolutionary.