📝 Paper Summary
Chain-of-Thought (CoT) reasoning
Transformer sample efficiency
Mechanistic interpretability
Learning theory for Transformers
Chain-of-thought enables Transformers to learn complex parity functions with polynomial samples by introducing sparse sequential dependencies that are naturally captured by sparse attention heads, whereas direct learning requires exponential samples.
Core Problem
Large language models struggle to learn certain simple algorithmic tasks (like parity) without exponential data, even when they theoretically have enough expressive power to represent the solution.
Why it matters:
- Theoretical studies often attribute CoT success merely to increased expressiveness, failing to explain why models fail on tasks they can technically represent
- Understanding sample efficiency is critical for tasks where data is scarce or reasoning steps are implicit
- Bridging the gap between theoretical expressiveness proofs and practical optimization difficulties reveals the true mechanism of CoT
Concrete Example:
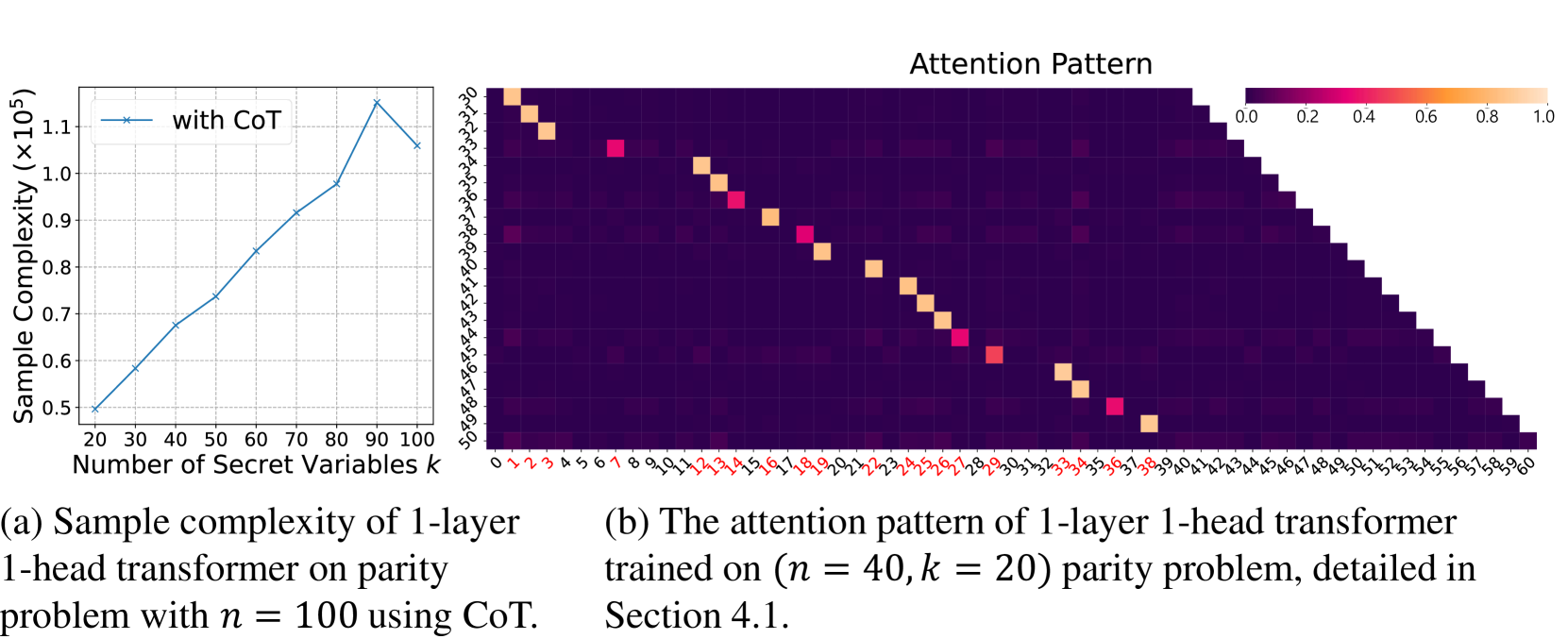
A 5-variable parity function f(b) = b1 ⊕ b2 ⊕ b4 requires identifying 3 specific variables out of many. Without CoT, a Transformer needs exponential samples to find this combination. With CoT (showing intermediate steps like 'b1', 'b1⊕b2', 'b1⊕b2⊕b4'), the model learns linearly.
Key Novelty
Sparse Dependence to Sparse Attention Mechanism
- Demonstrates that CoT breaks complex dependencies into a chain where each step depends on only a few previous tokens (sparse dependence)
- Proves that gradient descent naturally leverages this structure to learn sparse attention patterns (focusing on relevant previous steps) very efficiently
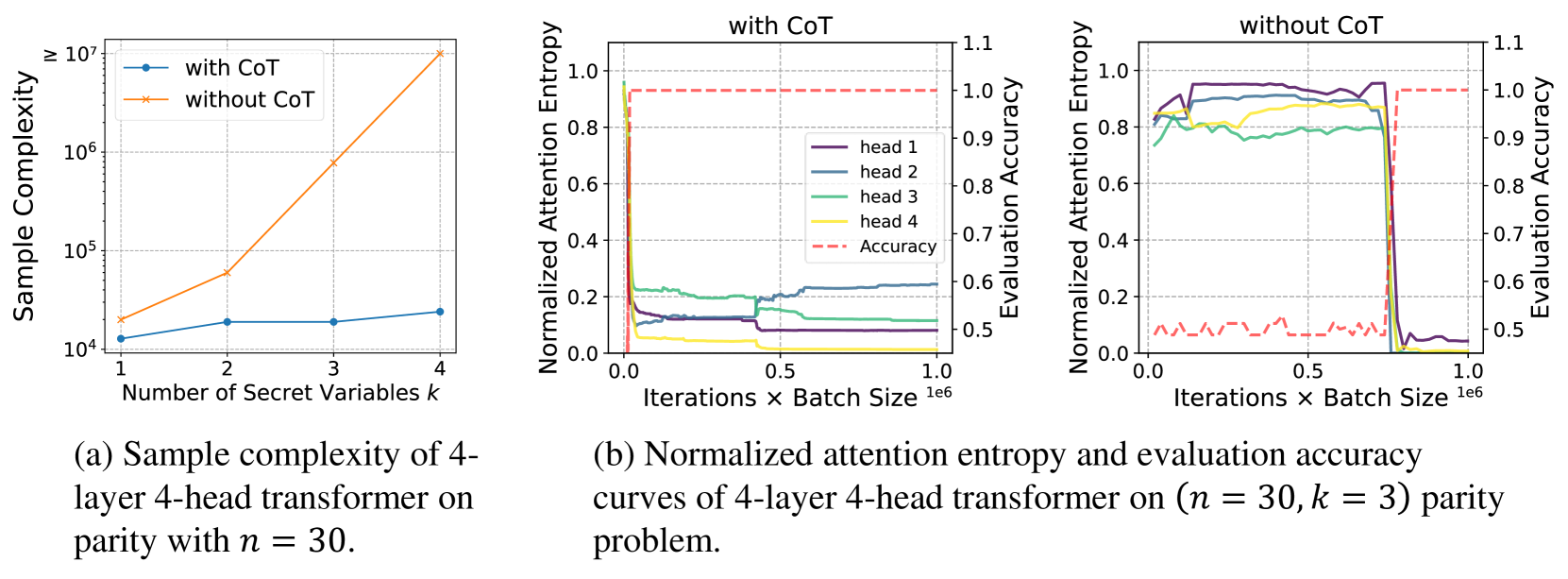
- Establishes a separation in sample complexity: Polynomial samples with CoT vs. exponential samples without CoT for the same function
Architecture
Conceptual flow: Input bits -> (Hidden/Implicit Computation) -> Output vs. Input bits -> Step 1 -> Step 2 -> Output. The paper does not have a dedicated system architecture diagram, but describes the data flow clearly.
Evaluation Highlights
- Without CoT, sample complexity grows exponentially with problem difficulty (k), reaching ~10^7 samples for k=12
- With CoT, sample complexity grows linearly, requiring < 10^5 samples even for k=12
- Theoretical proof shows CoT reduces sample requirement from 2^Ω(k) (exponential) to O(n) (linear) for parity learning
Breakthrough Assessment
8/10
Provides a rigorous theoretical foundation for why CoT works beyond just 'adding compute', proving an exponential separation in sample efficiency and linking it to attention sparsity.