📝 Paper Summary
Test-Time Compute (TTC) Scaling
Reasoning Models
Reward Modeling
VGS scales test-time compute by training a token-level value model on outcome-labeled traces—bypassing expensive step-level annotations—and guiding block-wise search with weighted majority voting.
Core Problem
Scaling test-time compute for reasoning models is hindered because defining "steps" for Process Reward Models (PRMs) is ambiguous in long contexts, and collecting step-wise labels is prohibitively expensive.
Why it matters:
- State-of-the-art reasoning models like DeepSeek-R1 require massive inference compute due to long Chain-of-Thought (CoT) traces
- Existing PRM methods struggle to scale because they rely on human or LLM-judge annotations for every step, which is costly and hard to define for continuous reasoning streams
- Models often get stuck in unproductive loops or generate repetitive content without granular guidance
Concrete Example:
When a reasoning model generates a long solution, standard PRMs look for newlines to define 'steps' to score. If the model outputs a 4000-token block of dense reasoning without clear delimiters, step-based PRMs fail to provide feedback. VGS avoids this by scoring arbitrary token blocks using a value model trained on final outcomes.
Key Novelty
Value-Guided Search (VGS)
- Trains a token-level value model using 'regression via classification' on full reasoning traces, predicting whether a partial trace will lead to a correct answer without needing intermediate step labels
- Performs block-wise beam search where the value model scores fixed-length token blocks (e.g., 4096 tokens), selecting the most promising paths to continue generation
- Aggregates final search results using Weighted Majority Voting (WMV) rather than Best-of-N, leveraging value scores to weight consensus
Architecture
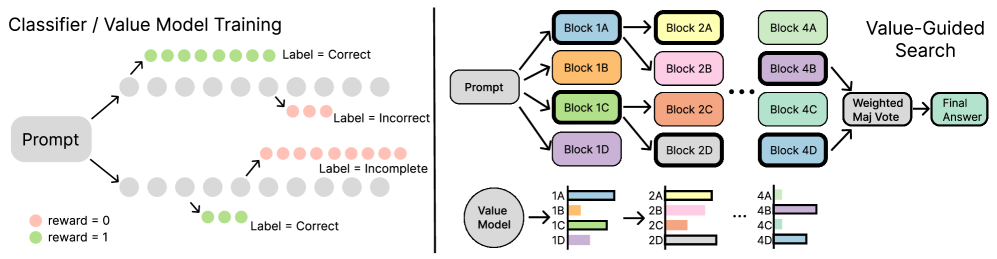
Data collection pipeline (Left) and Beam Search process (Right).
Evaluation Highlights
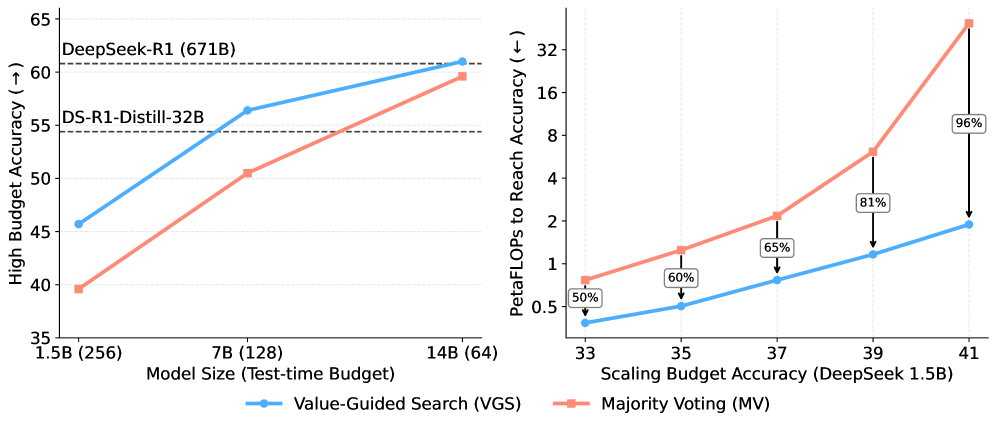
- VGS on DeepSeek-R1-Distill-Qwen-14B (total 15.5B params) matches the performance of the 671B DeepSeek-R1 on AIME/HMMT benchmarks with a budget of 64 generations
- VGS reduces average response length by over 12% (11,219 tokens vs 12,793) compared to the base DeepSeek-1.5B model while improving accuracy
- DeepSeek-VM-1.5B outperforms 7B baseline PRMs (Math-Shepherd and Qwen2.5-Math) when used for weighted majority voting or search guidance
Breakthrough Assessment
8/10
Offers a highly practical recipe for scaling test-time compute without expensive human/LLM step-labels. Matches 671B performance with ~15B models via search. The open-sourced 2.5M dataset is a significant resource.