📊 Experiments & Results
Evaluation Setup
Few-shot prompting (2, 4, or 8 seeds) on reasoning benchmarks. Inference uses greedy decoding.
Benchmarks:
- GSM8K (Grade School Math (Numerical))
- GSM-Hard (Hard Numerical Reasoning (Large Numbers))
- Repeat Copy (Algorithmic Reasoning (BigBench))
- Colored Objects (Symbolic Reasoning (BigBench))
- SVAMP (Math Word Problems)
Metrics:
- Accuracy
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Performance on Numerical Reasoning Tasks (using PAL-style code reasoning). | ||||
| GSM8K | Accuracy | 73.1 | 75.3 | +2.2 |
| GSM-Hard | Accuracy | 62.9 | 64.7 | +1.8 |
| SVAMP | Accuracy | 79.6 | 80.5 | +0.9 |
| Performance on Symbolic and Algorithmic Reasoning Tasks. | ||||
| Repeat Copy | Accuracy | 71.9 | 87.5 | +15.6 |
| Colored Objects | Accuracy | 93.4 | 93.6 | +0.2 |
Experiment Figures
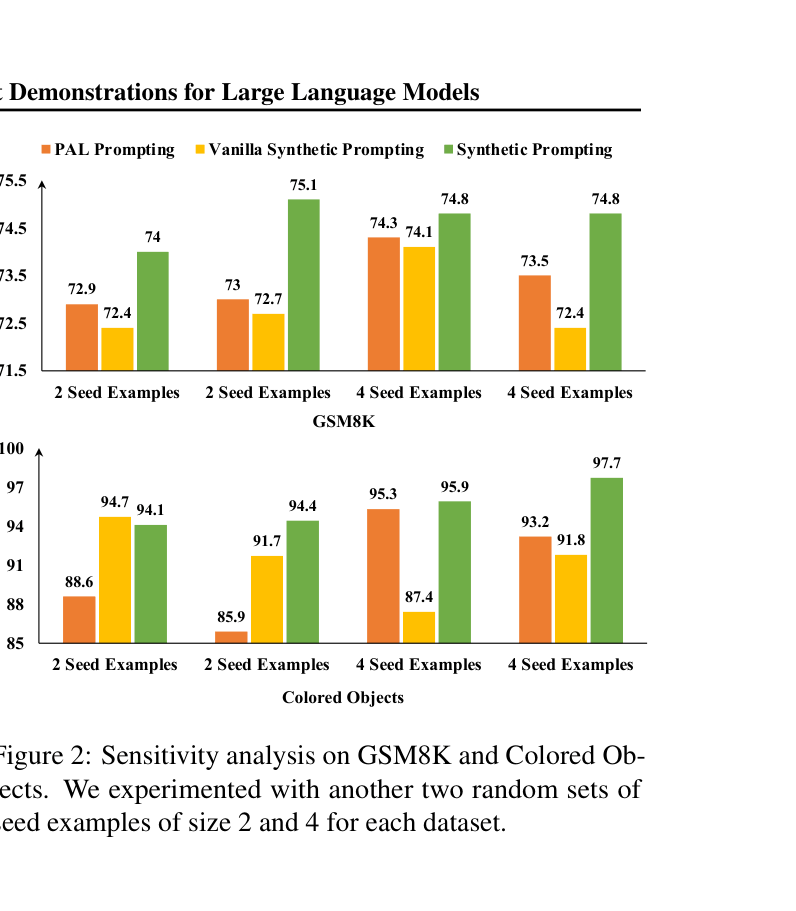
Sensitivity analysis bar charts showing accuracy on GSM8K and Colored Objects across 3 different random seeds.
Main Takeaways
- Synthetic Prompting consistently outperforms standard PAL prompting, especially when seed examples are scarce (2-4 examples).
- The method is particularly effective for algorithmic tasks (Repeat Copy) where expanding the diversity of input patterns via synthesis helps the model generalize.
- Ablations show that both 'Topic Word' (diversity) and 'Target Complexity' (difficulty) conditions are crucial; removing them degrades performance to near-baseline levels.
- In-Cluster Complexity selection is superior to random or similarity-based selection, confirming that prompt diversity and complexity are key drivers of reasoning performance.