📝 Paper Summary
Prompt Engineering
Chain-of-Thought Reasoning
Few-shot Learning
Strategic Chain-of-Thought improves LLM reasoning by explicitly eliciting a high-level problem-solving strategy before generating reasoning steps, reducing the likelihood of errors caused by unstable or complex valid paths.
Core Problem
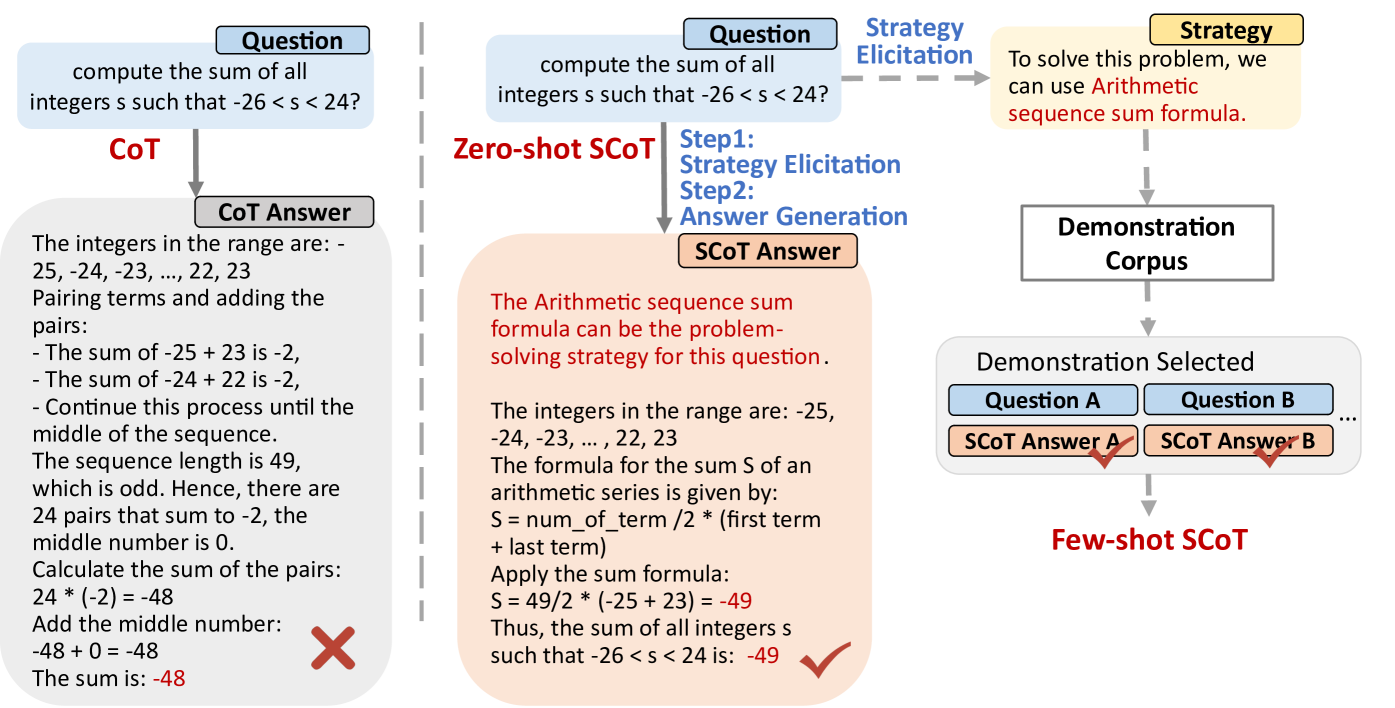
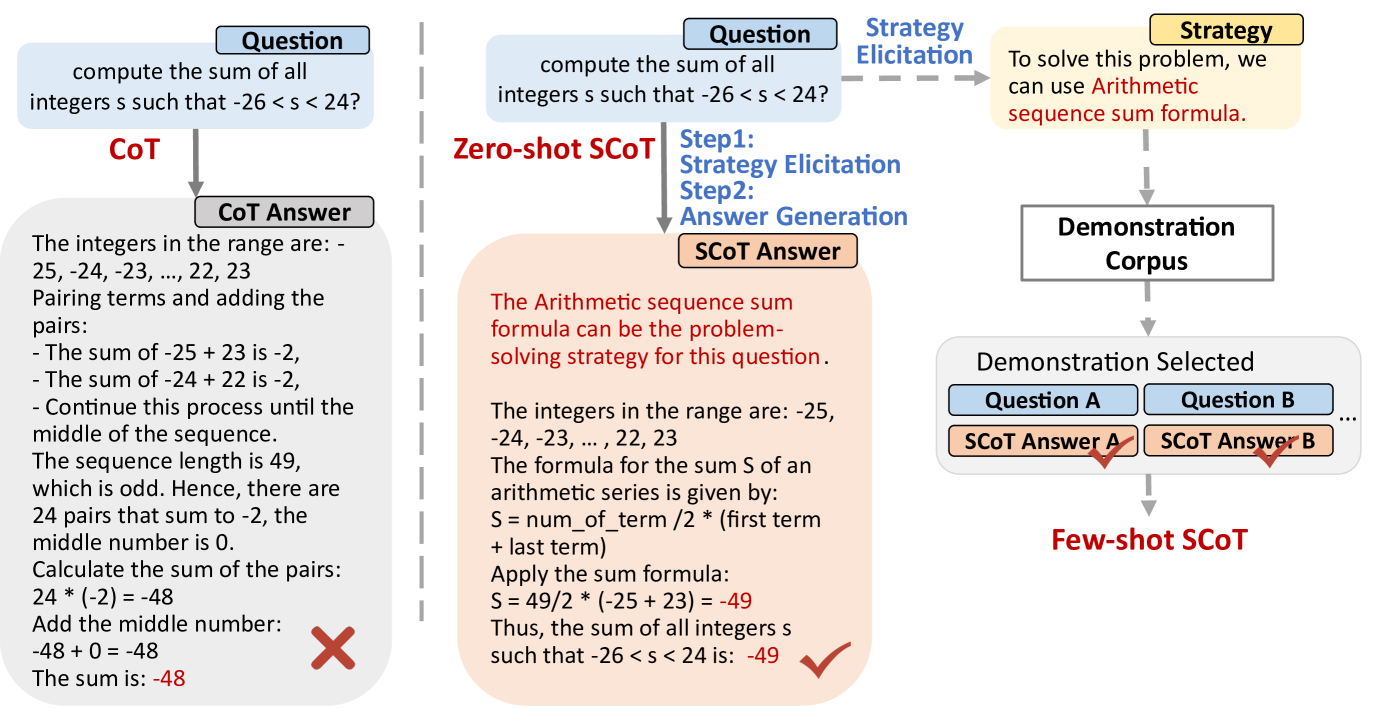
Standard Chain-of-Thought (CoT) often generates valid but sub-optimal reasoning paths that are prone to errors due to high cognitive load or unnecessary complexity.
Why it matters:
- Reliability in complex reasoning tasks (math, logic) is undermined when models choose convoluted solution paths that increase the chance of calculation or logic errors.
- Existing solutions like Self-Consistency require high computational resources (e.g., 40 queries), while others require external knowledge, making them inefficient.
Concrete Example:
When solving 'compute the sum of integers s such that -26 < s < 24', a model might list and sum all pairs (error-prone due to many steps). A better strategy is to use the arithmetic series formula directly. Standard CoT might pick the first, while SCoT elicits the formula strategy first.
Key Novelty
Two-stage Strategic Elicitation & Application
- Introduces a 'Strategic Knowledge' step within a single prompt where the model first identifies a general method (e.g., 'use the arithmetic series formula') before executing the specific steps.
- Uses this elicited strategy to retrieve and match few-shot demonstrations that share the same underlying problem-solving principle, rather than just surface-level similarity.
Architecture
The prompt template structure for Strategic Chain-of-Thought (SCoT).
Evaluation Highlights
- +21.05% accuracy improvement on GSM8K using Llama3-8b compared to Zero-shot CoT baseline.
- +24.13% accuracy improvement on Tracking_Objects dataset using Llama3-8b compared to Zero-shot CoT.
- Achieves comparable or better performance than Self-Consistency (which uses multiple queries) while using a single query structure in many cases.
Breakthrough Assessment
7/10
Significant performance gains on standard benchmarks with a relatively simple, resource-efficient prompting intervention. Bridges cognitive science theory with practical prompt engineering.