📝 Paper Summary
Chain-of-Thought (CoT) Reasoning
Language Agents
This comprehensive survey analyzes the foundational mechanics of Chain-of-Thought reasoning, maps its evolution into structured paradigms, and demonstrates how it serves as the cognitive engine for autonomous language agents.
Core Problem
While Large Language Models (LLMs) show emergent reasoning, the field lacks a unified understanding of *why* Chain-of-Thought (CoT) works, how its paradigms are shifting, and how it bridges the gap to autonomous agents.
Why it matters:
- Researchers need to understand the underlying conditions (model size, data structure) that make reasoning effective to avoid blindly applying CoT where it fails.
- The rapid evolution from simple prompts to complex structures (Trees/Graphs) and agents requires a systematic taxonomy to navigate future research directions.
- Connecting reasoning techniques to agentic behaviors (perception, memory) is crucial for building systems that can act in real-world environments.
Concrete Example:
In direct reasoning, an LLM might guess the elevation of a region incorrectly. With CoT, it breaks the problem down: search for 'Colorado orogeny', identify the 'High Plains', then search for 'High Plains elevation', leading to the correct range (1,800 to 7,000 ft).
Key Novelty
Unified Framework connecting CoT Mechanics to Agentic Systems
- Synthesizes theoretical proofs to explain that CoT works by identifying 'atomic knowledge' pieces that are strongly interconnected in the training data, forming localized clusters.
- Categorizes paradigm shifts in CoT into three dimensions: prompting patterns (manual vs. automatic), reasoning formats (linear vs. tree/graph), and application scenarios.
- Proposes a framework where CoT serves as the reasoning core for language agents, orchestrating perception, memory, and action execution in physical or virtual environments.
Architecture
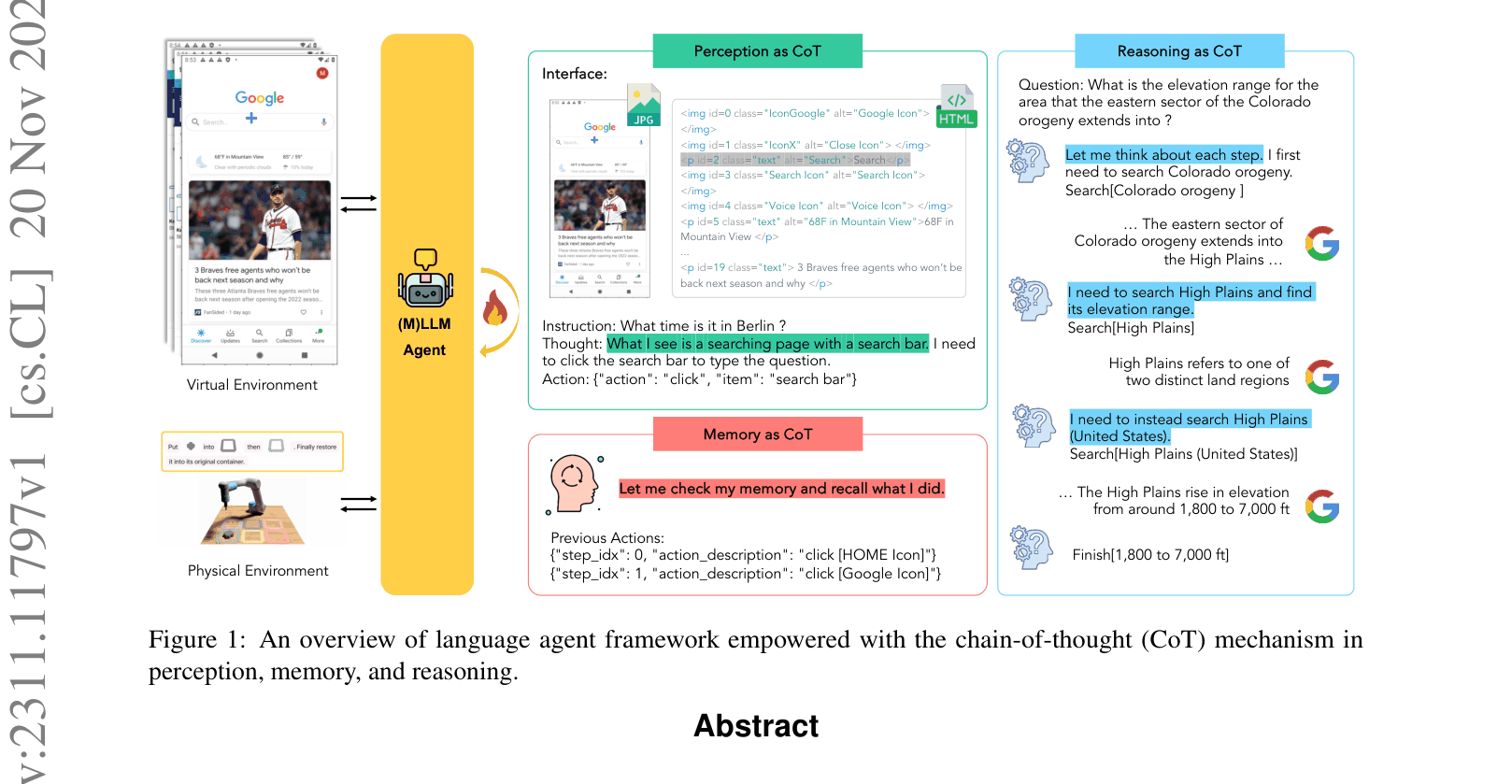
An overview of the language agent framework empowered by CoT, integrating Perception, Memory, and Reasoning.
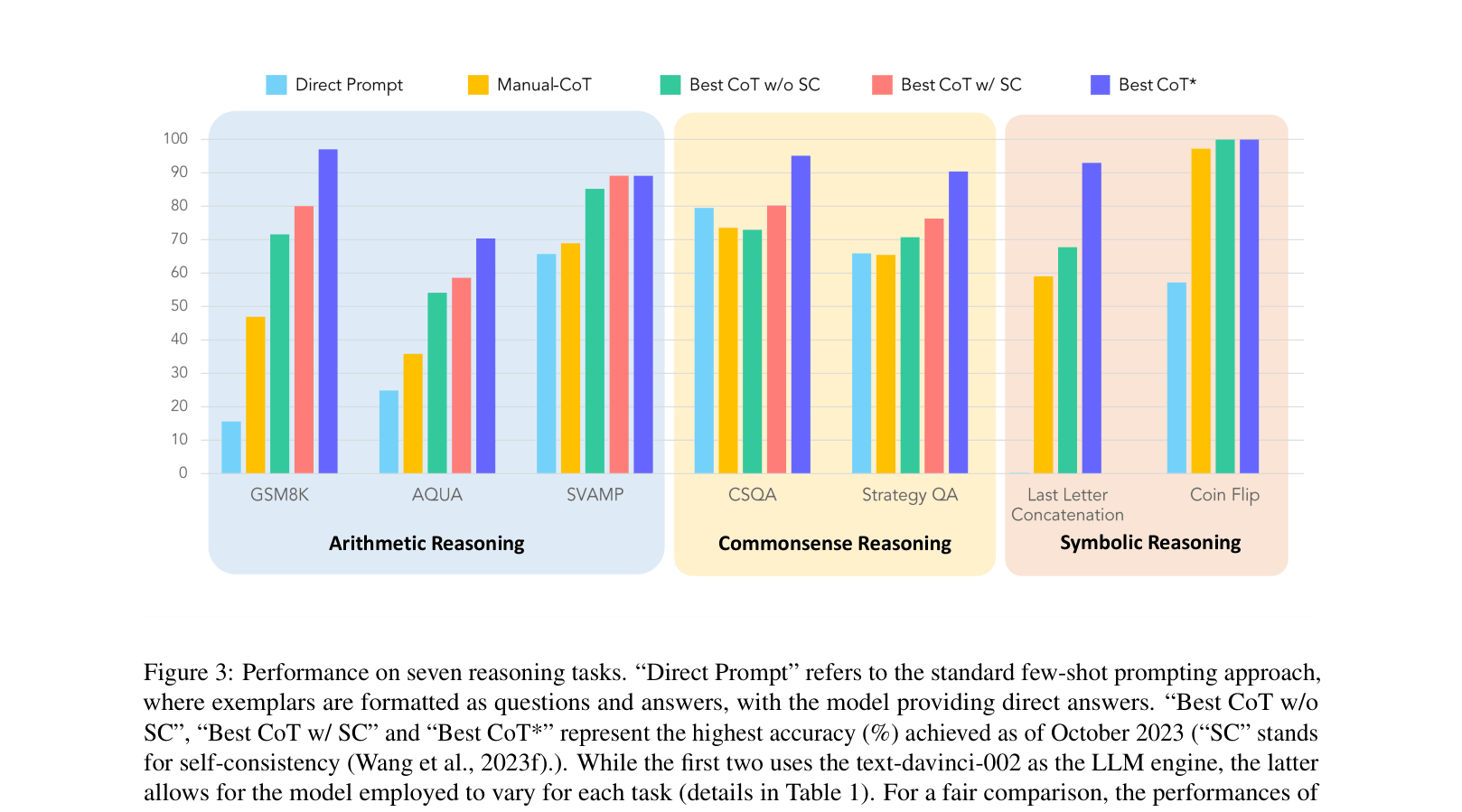
Evaluation Highlights
- On GSM8K (arithmetic reasoning), CoT-based methods achieve up to 97.00% accuracy using GPT-4 Code Interpreter, compared to lower baselines without tool use.
- On Coin Flip (symbolic reasoning), Auto-CoT achieves 99.90% accuracy using text-davinci-002, significantly outperforming direct prompting.
- On CSQA (commonsense reasoning), Manual-CoT with Self-Consistency achieves 95.10% accuracy using PaLM 2, demonstrating CoT's efficacy when scaled with model size.
Breakthrough Assessment
9/10
A definitive survey that not only catalogues the state-of-the-art but provides a theoretical grounding for why these methods work and structures the emerging field of agentic AI.