📊 Experiments & Results
Evaluation Setup
Safety evaluated on refusal benchmarks and adversarial attacks; Utility evaluated on math/code/general benchmarks.
Benchmarks:
- StrongReject (Direct refusal to harmful prompts)
- BeaverTails (Robustness against subtle jailbreaks)
- MATH500, GPQA, AIME24 (Mathematical reasoning)
- MBPP (Code generation)
Metrics:
- Attack Success Rate (ASR)
- Harmfulness Score (BeaverTails)
- Accuracy (Math/Code benchmarks)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
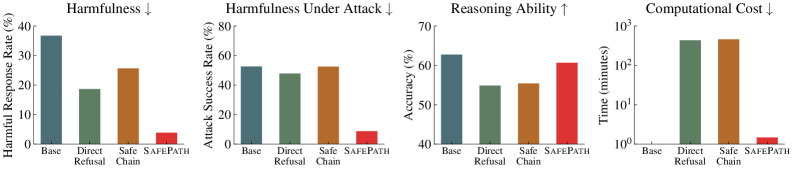
| Safety performance results showing SafePath's effectiveness in reducing harmfulness and blocking jailbreaks compared to the unaligned Base model. | ||||
| BeaverTails | Harmfulness Score (lower is better) | 45.1 | 4.5 | -40.6 |
| Adversarial Attacks (Avg ASR) | Attack Success Rate | 76.2 | 12.7 | -63.5 |
| Reasoning capability results demonstrating that SafePath preserves utility better than baselines like Direct Refusal. | ||||
| AIME24 | Accuracy | 55.4 | 54.4 | -1.0 |
| MATH500 | Accuracy | 82.8 | 83.6 | +0.8 |
| Training efficiency comparison showing SafePath's massive speedup over standard alignment methods. | ||||
| Training Time | Relative Speedup (vs SafeChain) | 1.0 | 314.1 | 313.1 |
Experiment Figures
Radar chart comparing Safety (ASR, Refusal) and Utility (Math, Code) metrics across Base, Direct Refusal, SafeChain, and SafePath.

Visualization of reasoning traces showing the Safety Primer activation.
Main Takeaways
- SafePath drastically reduces harmfulness and jailbreak success rates while incurring negligible loss in reasoning performance, effectively solving the 'Safety Tax' problem for LRMs.
- The method exhibits an emergent property where the safety primer ('Let's think about safety first') is autonomously reactivated by the model later in the reasoning chain for adversarial prompts, despite being trained only as a prefix.
- Traditional LLM safety methods (Circuit Breakers) and rigid LRM methods (Direct Refusal) fail to balance safety and utility in reasoning models, whereas SafePath succeeds by leveraging the model's own reasoning capabilities.
- Training is exceptionally efficient (minutes vs hours), making it highly practical for deployment.