📝 Paper Summary
Multimodal Reasoning
Chain-of-Thought (CoT) Prompting
Knowledge Distillation
T-SciQ improves multimodal science question answering by training a small student model on a mix of simple Chain-of-Thought and complex Plan-based Chain-of-Thought rationales generated by a Large Language Model.
Core Problem
Existing Multimodal-CoT methods rely on human-annotated rationales, which are costly to collect and often lack essential external information or accuracy due to limited annotator expertise.
Why it matters:
- Human annotation for complex scientific reasoning is expensive and time-consuming
- Annotators often miss external knowledge required for correct reasoning
- Captioning-based approaches lose visual information in complex images
Concrete Example:
In a science question about animal classification (Figure 1), a human annotator might provide a simple rationale missing the specific biological definition, whereas an LLM can generate a detailed explanation involving external knowledge. Furthermore, simple CoT fails on complex multi-step problems where planning is needed.
Key Novelty
T-SciQ (Teaching Science Question Answering)
- Generates two types of teaching data from an LLM: standard CoT for simple problems and Plan-based CoT (PCoT) for complex problems requiring decomposition
- Uses a data mixing strategy governed by validation set performance to assign the optimal teaching rationale type (CoT vs. PCoT) to each skill category
- Trains a smaller student model using a two-stage framework (rationale generation then answer inference) with these mixed synthetic signals
Architecture
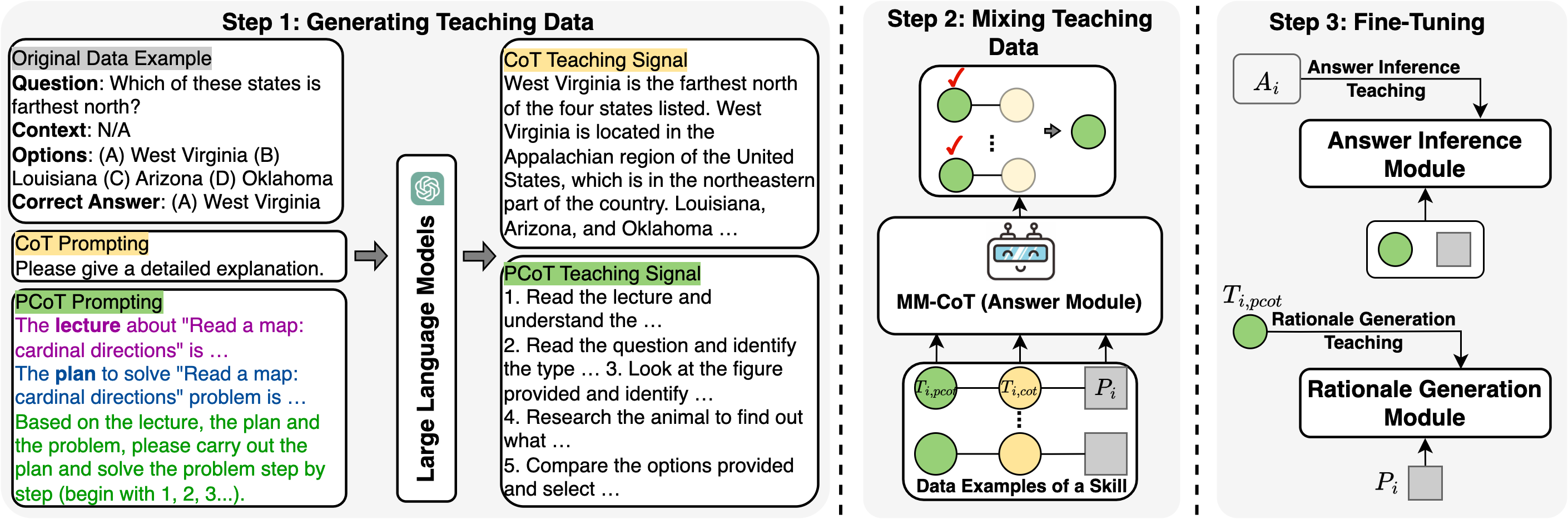
The T-SciQ framework pipeline, including Teaching Data Generation, Data Mixing, and Two-stage Fine-tuning.
Evaluation Highlights
- Achieves 96.18% accuracy on ScienceQA, setting a new state-of-the-art
- Outperforms the best GPT-4 based few-shot baseline by 9.64%
- Surpasses human performance (88.40%) by 7.78%
Breakthrough Assessment
9/10
Significant leap in performance on a major benchmark (ScienceQA), surpassing GPT-4 and human baselines by large margins using a smaller distilled model.