📝 Paper Summary
Zero-shot Reasoning
Prompt Engineering
Interpretability
The paper proposes an instance-adaptive prompting strategy (IAP) that selects the best zero-shot prompt for each specific question by analyzing internal information flow (saliency scores) between the question, prompt, and rationale.
Core Problem
Existing Zero-shot CoT methods use a single task-level prompt (e.g., 'Let's think step by step') for all instances, but a prompt that works well for the dataset on average may fail on specific instances.
Why it matters:
- Task-level optimal prompts can have adverse effects on certain hard instances, leading to reasoning failures
- Understanding why some prompts succeed while others fail for specific questions remains a 'black box' mystery in current research
- No existing method adaptively selects zero-shot prompts based on internal model mechanics rather than external performance proxies
Concrete Example:
For a simple math question in GSM8K, the standard prompt 'Let's think step by step' causes the model to overcomplicate and fail, whereas the generally weaker prompt 'Don't think. Just feel.' produces the correct answer.
Key Novelty
Instance-Adaptive Prompting (IAP) via Information Flow Analysis
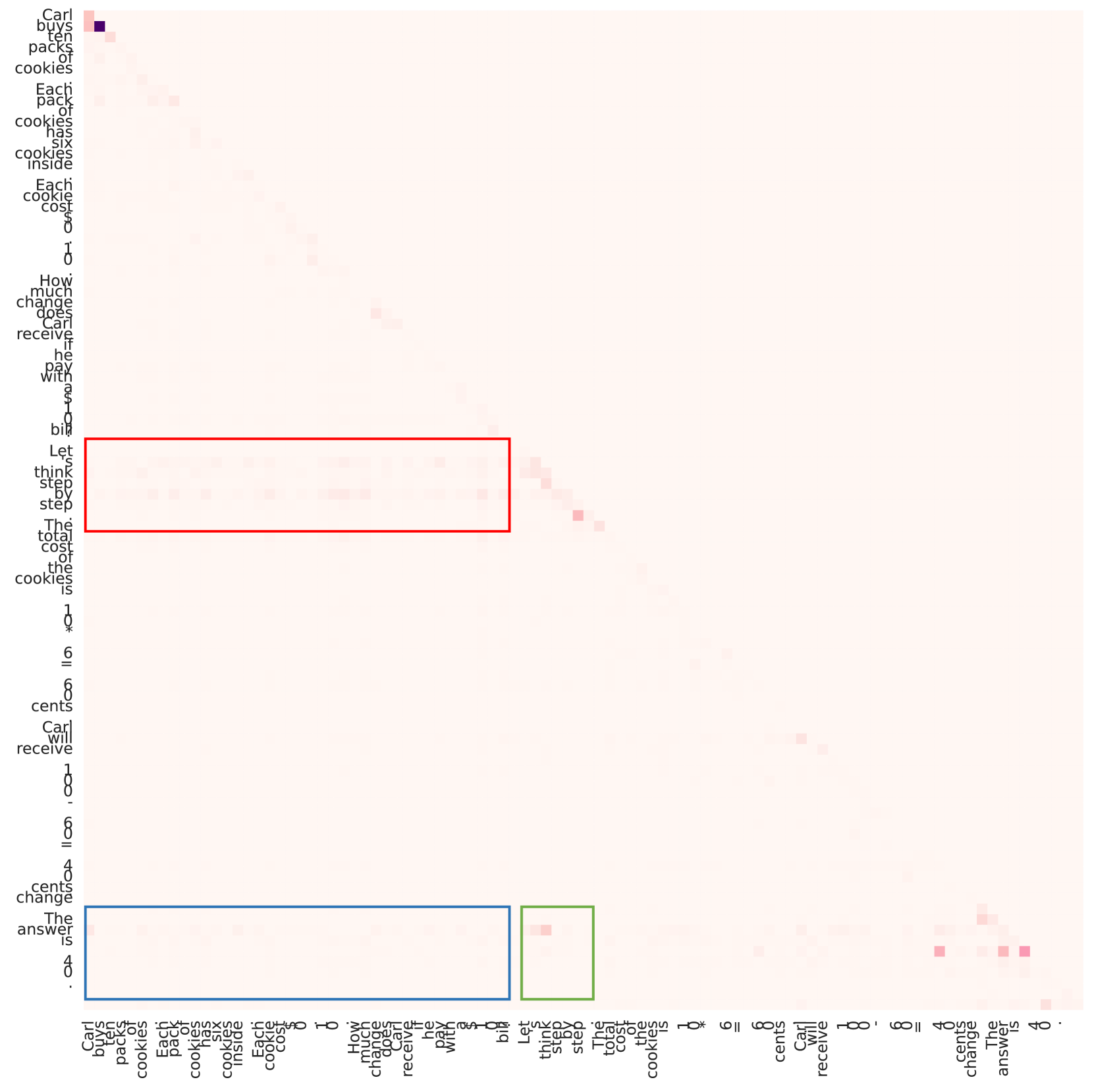
- Analyzes 'saliency scores' (attention gradients) to quantify how much information flows from the Question to the Prompt, and from both to the Rationale during inference
- Discovers that successful reasoning is characterized by high information flow from Question→Prompt in shallow layers and Question+Prompt→Rationale in later layers
- Selects the best prompt for a given instance by calculating these saliency metrics for a candidate set and picking the one with the strongest relevant information flow patterns
Architecture
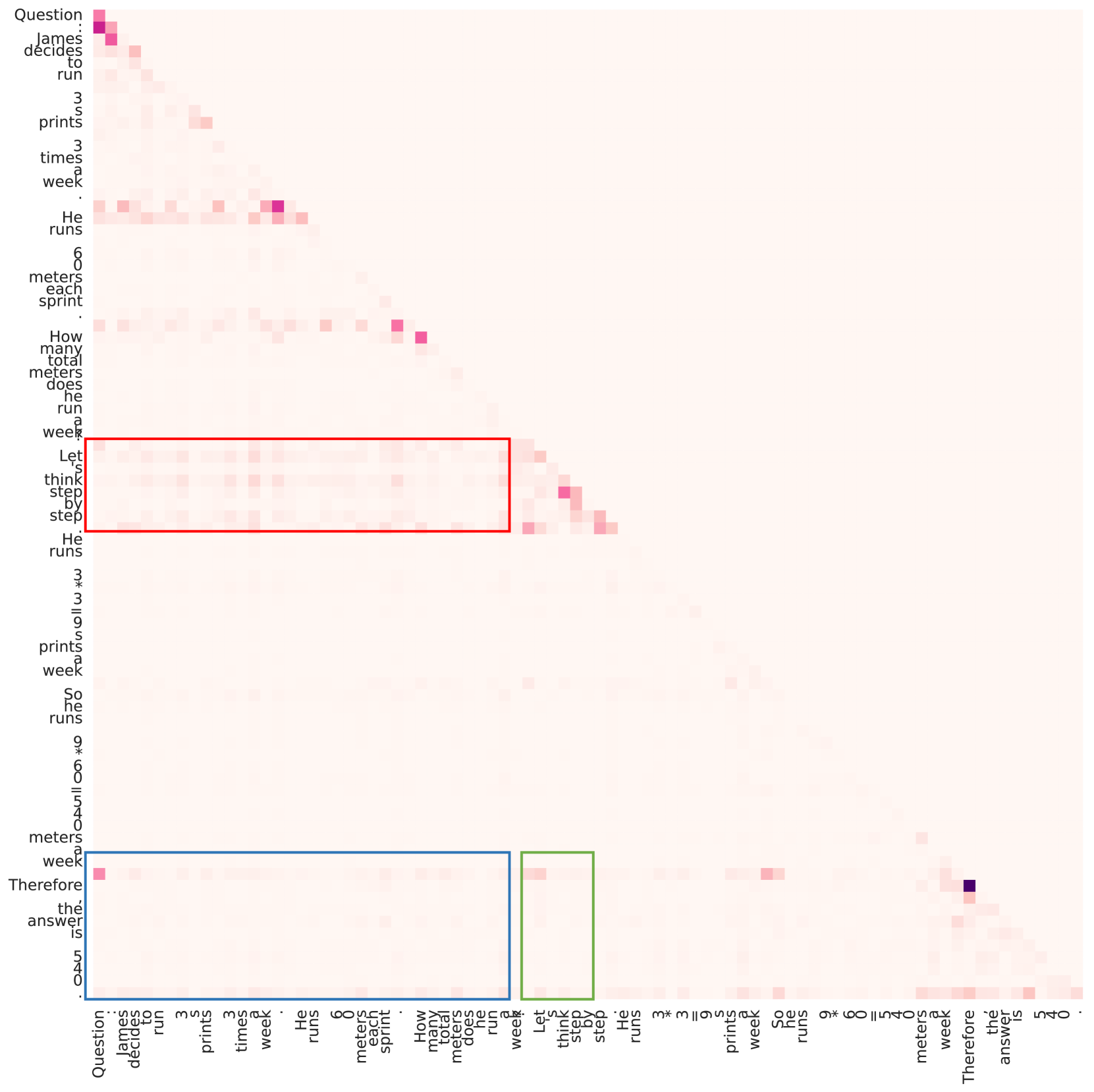
Visualization of saliency score matrices for 'Good' vs 'Bad' reasoning instances. It shows heatmaps of attention gradients between Question, Prompt, and Rationale tokens.
Evaluation Highlights
- +2% to +4% accuracy improvement across GSM8K, MMLU, and Causal Judgement compared to optimal task-level prompts on models like Llama-2-13B-Chat and Qwen-14B-Chat
- IAP consistently outperforms strong baselines like Plan-and-Solve and Self-Discover on multiple reasoning tasks
- Analysis reveals that good prompts effectively aggregate question information in shallow layers, acting as a catalyst for later reasoning steps
Breakthrough Assessment
7/10
Provides a novel mechanistic interpretation of Zero-shot CoT success (information flow) and successfully operationalizes it into a practical prompting strategy that beats static baselines.