📝 Paper Summary
Chain-of-Thought Reasoning
Instruction Tuning
The CoT Collection augments 1.84 million rationales across 1,060 tasks to equip smaller language models (3B–11B) with zero-shot chain-of-thought reasoning capabilities previously limited to large models.
Core Problem
Small language models (<100B parameters) fail to perform chain-of-thought reasoning on unseen tasks because existing CoT instruction datasets are too small (only ~9 tasks), leading to poor generalization.
Why it matters:
- Chain-of-Thought prompting typically requires massive models (>100B params), making reasoning capabilities inaccessible due to high computational costs
- Current small LMs struggle to generalize reasoning skills to novel tasks, often failing to generate rationales even when prompted
- Relying on single-task CoT fine-tuning does not solve the broader problem of zero-shot generalization across diverse unseen domains
Concrete Example:
When asked a complex boolean expression question, a standard small LM (like Flan-T5) directly outputs a potentially incorrect answer. In contrast, CoT-T5 trained on the CoT Collection first generates 'Let's think step by step' followed by a logical breakdown, leading to the correct result.
Key Novelty
Large-Scale Rationale Distillation for Instruction Tuning
- Augments the existing Flan Collection by generating 1.84 million chain-of-thought rationales for 1,060 tasks using a large teacher model (Codex)
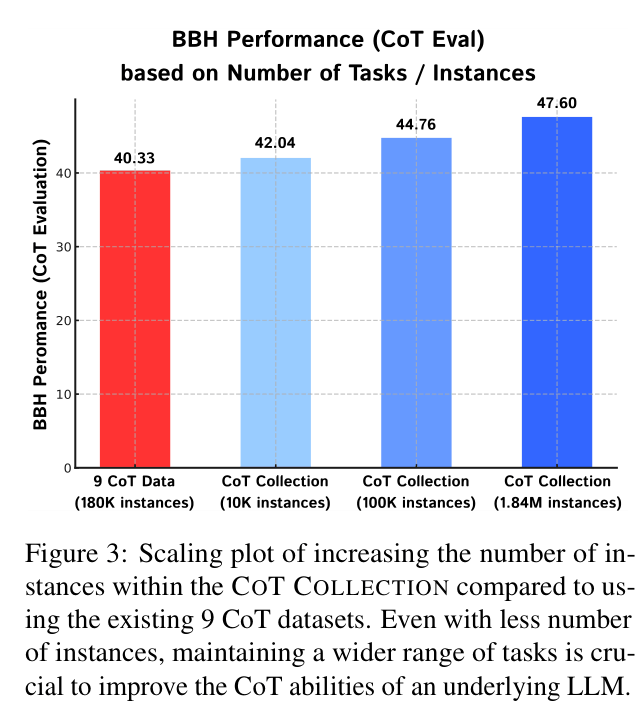
- demonstrates that fine-tuning small LMs on a massive diversity of reasoning tasks (1,060) is far more effective than scaling up examples on a few tasks (9)
- Introduces CoT-T5, a model that learns to consistently generate step-by-step reasoning before answering, even on unseen tasks
Architecture
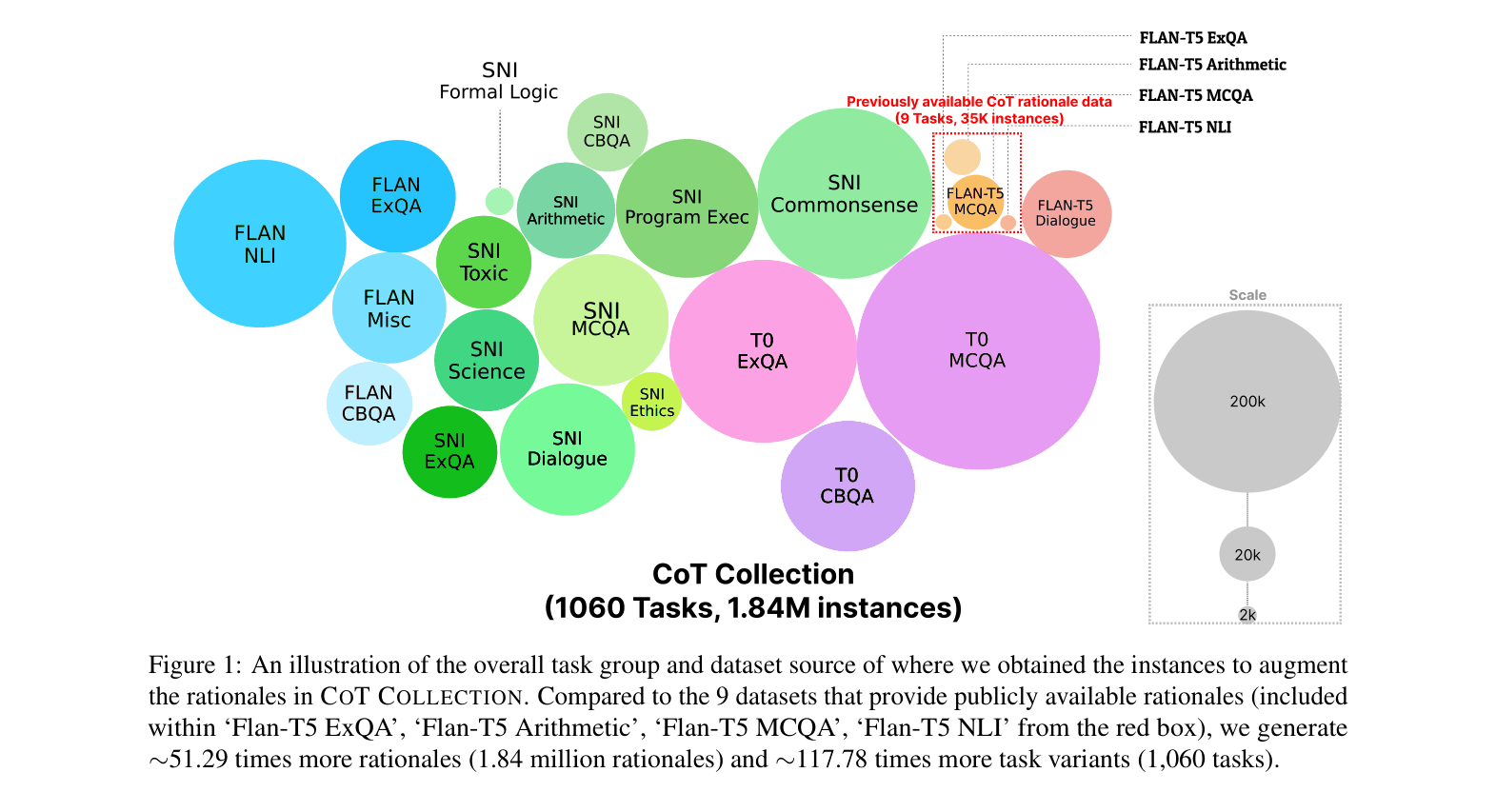
Conceptual comparison between the CoT Collection and previous CoT datasets
Evaluation Highlights
- +4.34% improvement in zero-shot accuracy on Big Bench Hard (BBH) for Flan-T5 (3B) using CoT evaluation
- +13.98% improvement over ChatGPT on few-shot domain-specific tasks (legal/medical) when using CoT-T5-11B with LoRA
- Outperforms T0-3B by +8.65% on the P3 benchmark by training on only 163 tasks (vs. T0's original training setup)
Breakthrough Assessment
8/10
Significantly democratizes reasoning capabilities for smaller, deployable models by providing a massive, high-quality open-source dataset and proving that task diversity drives CoT generalization.