📝 Paper Summary
Faithfulness in Large Language Models
Chain-of-Thought Reasoning
Causal Analysis of LLMs
The paper uses causal mediation analysis to show LLMs often ignore their own reasoning steps and proposes FRODO, a framework that trains separate inference and reasoning modules with counterfactual and preference objectives to force the answer to faithfully follow the reasoning.
Core Problem
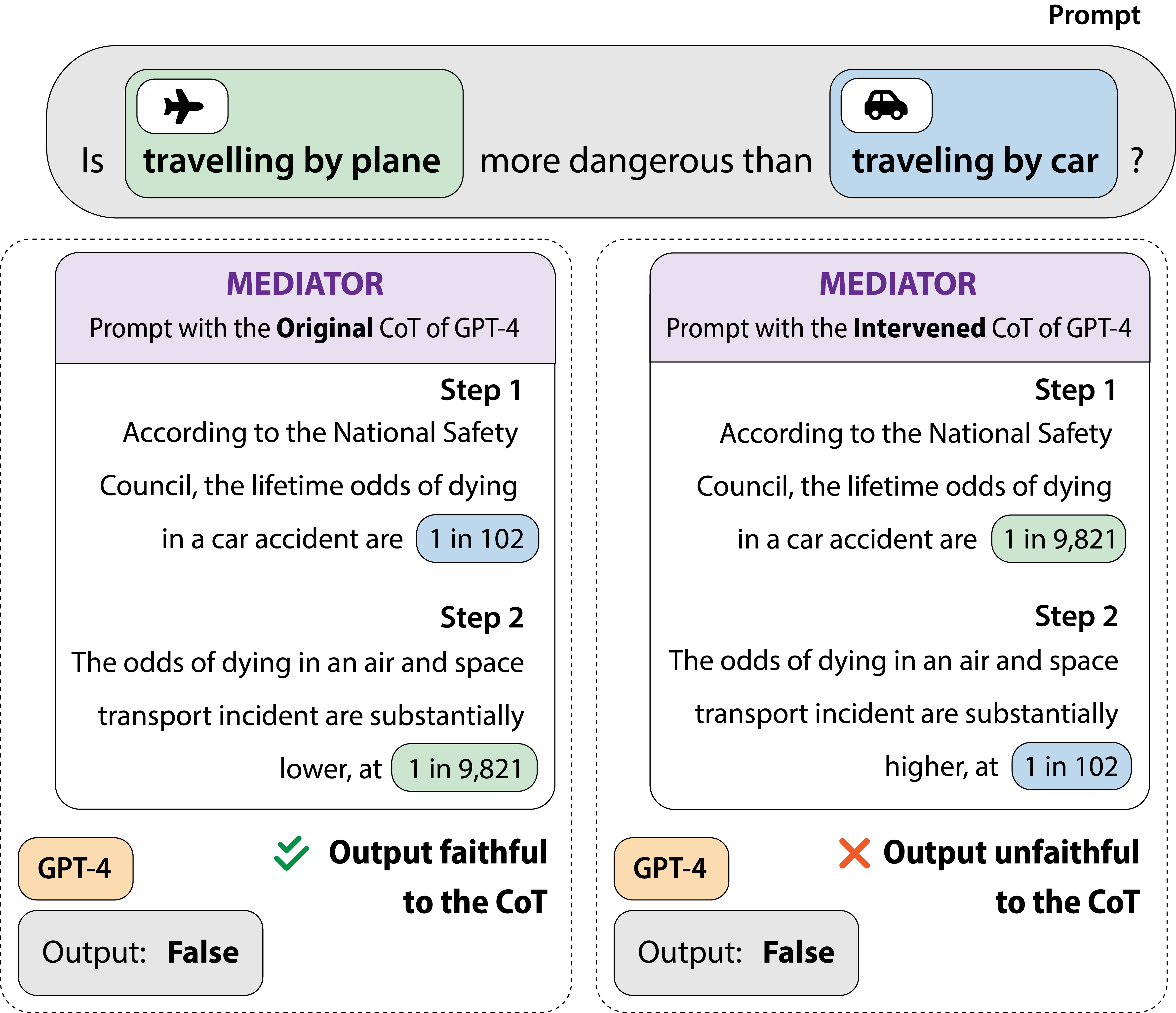
Large language models often generate 'unfaithful' Chain-of-Thought explanations, where the final answer does not causally depend on the generated reasoning steps, acting instead as a post-hoc justification.
Why it matters:
- If reasoning is merely post-hoc, users cannot trust the model's explanations to diagnose errors or verify safety
- Models that ignore their own reasoning steps are less robust to perturbations and generalize poorly to out-of-distribution tasks
- Prior methods focus on task performance (accuracy) rather than the causal validity of the reasoning process
Concrete Example:
In a causal intervention study, when GPT-4 is provided with a perturbed, counterfactual reasoning chain that logically contradicts its original answer, it faithfully changes its answer only 30% of the time, effectively ignoring the provided logic to stick to its prior bias.
Key Novelty
FRODO (Framework for Reasoning and Optimization with DPO and Objectives)
- Decomposes reasoning into two distinct modules: an Inference Module that generates reasoning steps and a Reasoning Module that predicts the answer based on those steps
- Uses Causal Mediation Analysis as a training signal, optimizing the Reasoning Module to maximize the 'Indirect Effect' (how much the reasoning actually changes the answer)
- Trains the Inference Module using Direct Preference Optimization (DPO) to prefer correct reasoning chains over irrelevant or counterfactual ones without explicit human labeling
Architecture
A Causal Mediation Analysis graph visualizing the relationship between Input (X), Reasoning Chain (R), and Final Answer (Y).
Evaluation Highlights
- +2% to +3% absolute accuracy improvement over standard supervised fine-tuning and CoT distillation methods across four reasoning tasks
- +4.5% improvement in robustness (faithfulness), measured by how reliably the model alters its answer when conditioned on counterfactual reasoning chains
- +2.6% performance improvement on out-of-distribution test sets compared to supervised fine-tuning, indicating better generalization
Breakthrough Assessment
7/10
Novel application of Causal Mediation Analysis not just for evaluation but as a training objective. Addresses the critical 'hallucinated reasoning' problem directly, though improvements are incremental.