📝 Paper Summary
Financial Natural Language Processing (FinNLP)
Prompt Engineering
Chain-of-Thought Reasoning
FinCoT enhances Large Language Model performance on financial tasks by injecting expert reasoning blueprints (encoded as Mermaid diagrams) into a structured Chain-of-Thought prompt without requiring model fine-tuning.
Core Problem
General-purpose Chain-of-Thought prompting lacks domain-specific constraints, leading LLMs to omit critical financial checks (e.g., valuation, unit conversion) or use incorrect formulas.
Why it matters:
- Financial decision-making requires precise mathematics and adherence to standard workflows (e.g., discounting, portfolio attribution) that generic models often miss.
- Existing solutions rely on fine-tuning or few-shot exemplars, which demand labeled data and lack explicit control over the intermediate reasoning structure.
- Lack of interpretability and alignment with expert practice in current financial LLMs hinders their adoption in regulated high-stakes environments.
Concrete Example:
In finance, a model might confuse basis points with percentages or skip a valuation check. FinCoT prevents this by forcing the model to follow a blueprint that explicitly lists 'Check Units' or 'Apply Discount Formula' as mandatory steps.
Key Novelty
FinCoT (Financial Chain-of-Thought)
- Embeds domain-specific 'expert blueprints' (visualized as Mermaid diagrams) directly into the prompt as a hint, guiding the model through a standard professional workflow.
- Uses a structured tag-based format (<thinking>, <output>) combined with a 'semi-reflection' step where the model verifies its own reasoning before finalizing the answer.
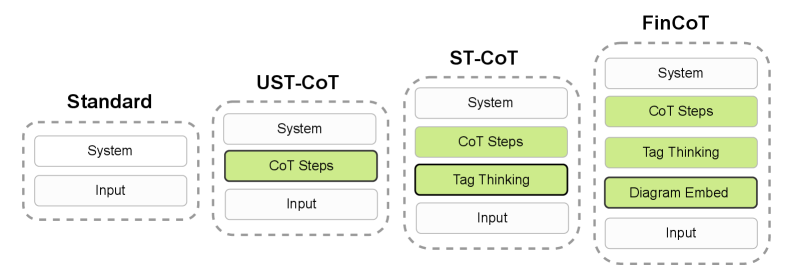
Architecture
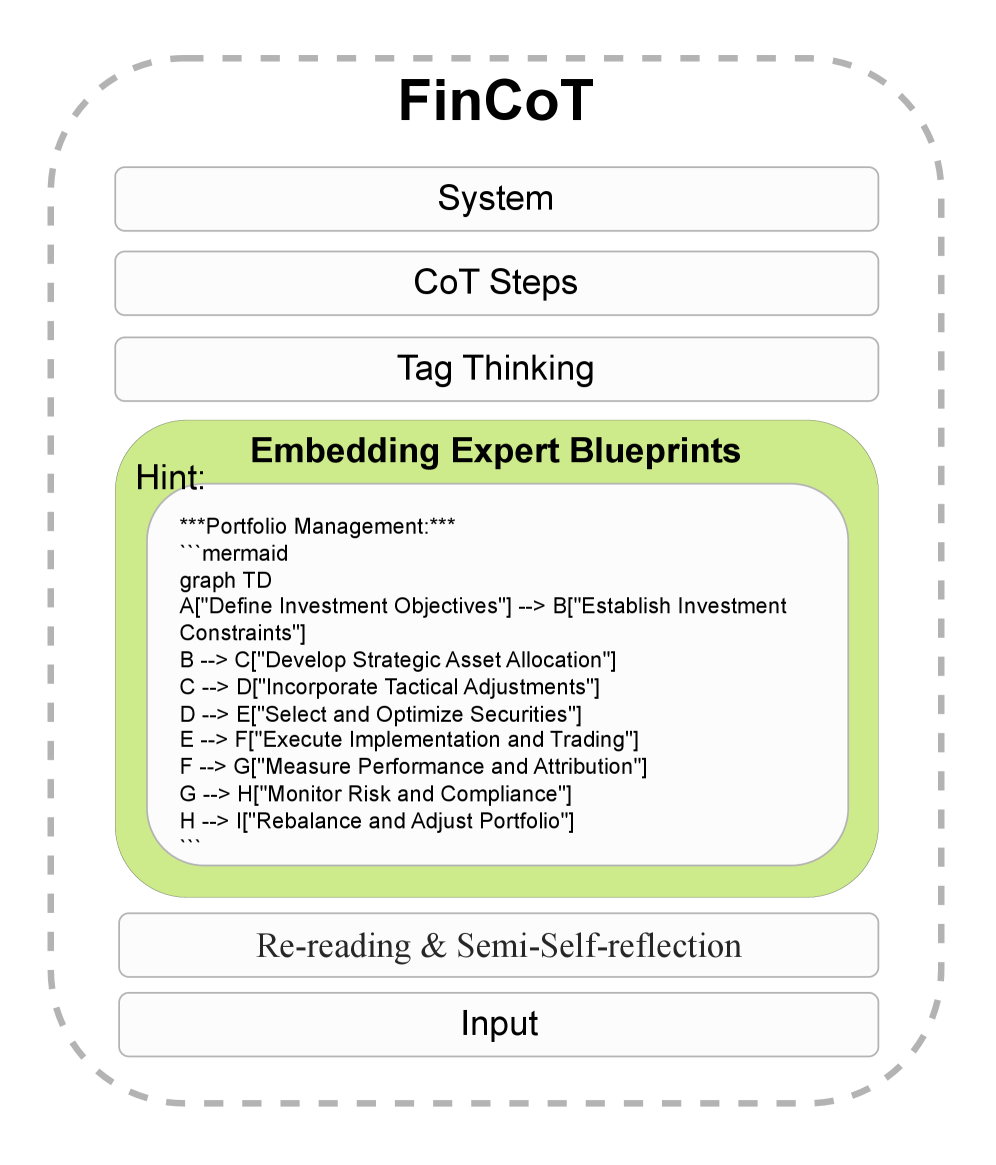
The FinCoT prompting framework structure compared to standard inputs.
Evaluation Highlights
- Boosts Qwen3-8B-Base accuracy from 63.2% (Standard Prompting) to 80.5% (+17.3pp) on CFA-style questions.
- Improves Fin-R1 (7B) accuracy from 65.7% to 75.7% (+10.0pp), showing benefits even for domain-specific models.
- Reduces output token length by ~8x compared to unstructured Chain-of-Thought while improving reasoning clarity.
Breakthrough Assessment
7/10
Significant accuracy gains and efficiency improvements without fine-tuning. The use of Mermaid diagrams as prompt constraints is a clever, interpretable innovation, though tested primarily on CFA-style multiple-choice questions.