📝 Paper Summary
Embodied AI
Vision-Language Pre-training
Robotic Manipulation
EmbodiedGPT aligns a frozen Large Language Model with a vision encoder using a new Chain-of-Thought dataset (EgoCOT) to generate executable plans that guide low-level robotic control policies.
Core Problem
Existing embodied agents struggle to generate high-quality, executable plans because generic vision-language datasets lack structured, step-by-step physical reasoning, and there is a disconnect between high-level language plans and low-level control actions.
Why it matters:
- General-purpose VLM captions (e.g., 'opening a door') are too vague for robots that need precise sub-goals (e.g., 'grasp handle', 'pull right').
- Without a mechanism to connect high-level reasoning to low-level motor control, LLM capabilities cannot be effectively translated into physical success in robotics.
Concrete Example:
In a 'sliding door' task, a standard model might just caption the scene. EmbodiedGPT generates a specific plan: '1. Move to left, 2. Grip handle, 3. Pull right'. The system then uses this text plan to query visual features specifically relevant to the handle and door, enabling the policy to execute the action.
Key Novelty
EgoCOT Dataset & Closed-Loop Embodied Control
- Constructs 'EgoCOT', a dataset of 2M+ annotated video clips with 'Chain-of-Thought' planning instructions (generated by ChatGPT, filtered by CLIP, human-verified) to teach step-by-step physical reasoning.
- Introduces a closed-loop mechanism where the LLM-generated plan is fed back into the vision module (Embodied-Former) to extract task-relevant 'instance features' (like a handle's position) for the low-level policy network.
Architecture
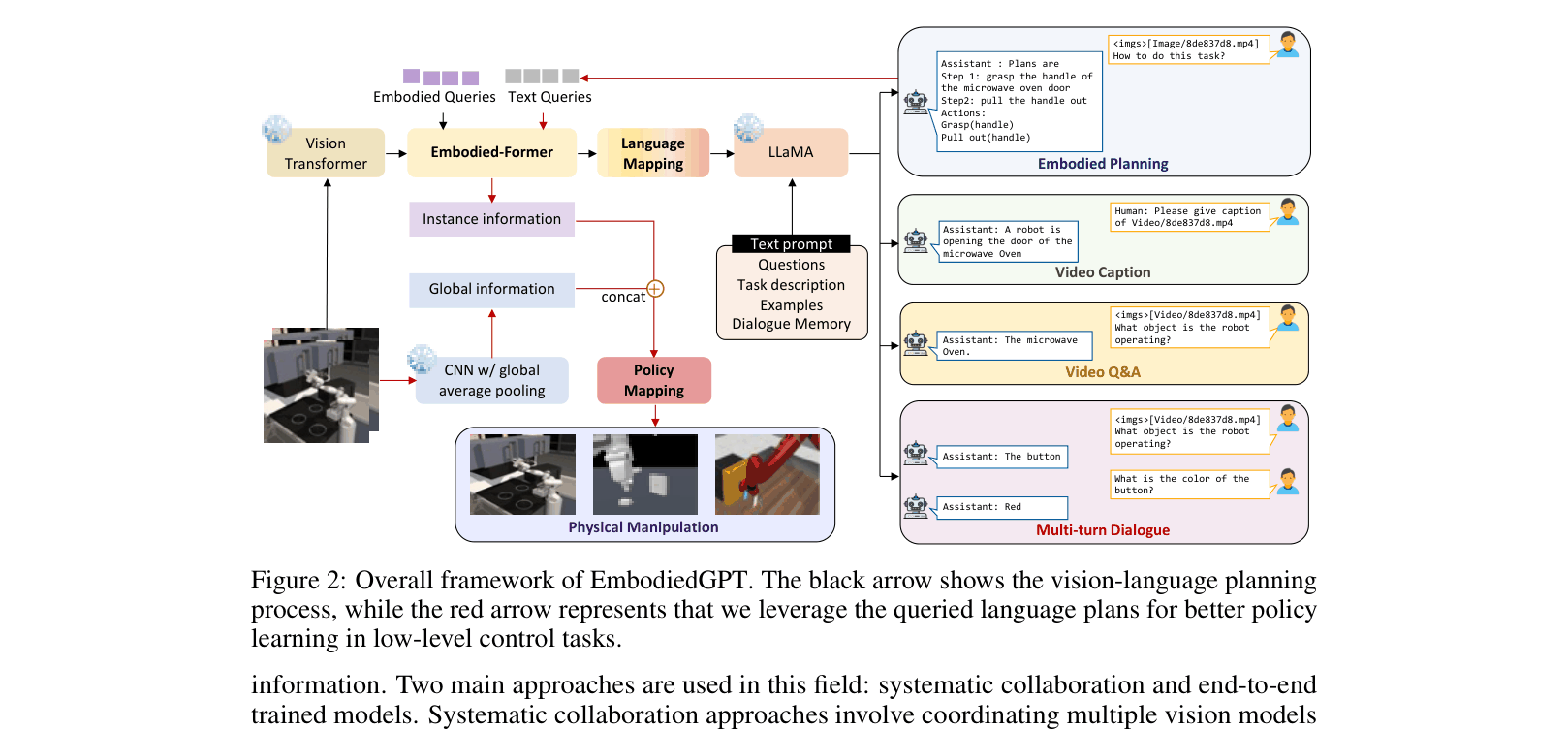
The overall framework of EmbodiedGPT, detailing the flow from visual input to embodied planning and finally to low-level control.
Evaluation Highlights
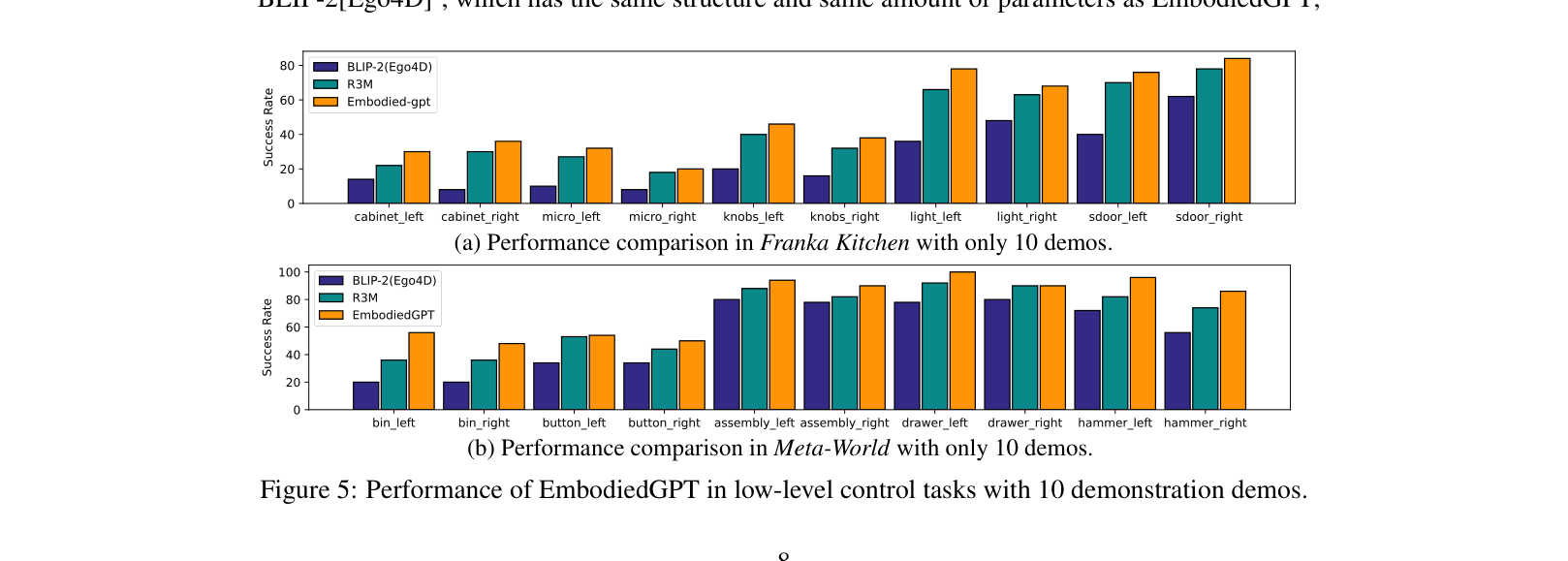
- Outperforms BLIP-2 (fine-tuned on Ego4D) by 22.1% on the Franka Kitchen benchmark (10-shot setting), showing the value of Chain-of-Thought pre-training.
- Surpasses state-of-the-art R3M by 4.2% on the Meta-World benchmark (10-shot setting) using the proposed closed-loop control paradigm.
- Achieves 76.4% success rate on Meta-World (10 demos), significantly higher than the 62.7% achieved when the closed-loop planning-to-control connection is removed.
Breakthrough Assessment
8/10
Strong contribution in bridging the gap between LLM reasoning and low-level control via a novel dataset and feedback loop mechanism. Significant empirical gains on standard robotic benchmarks.