📊 Experiments & Results
Evaluation Setup
Safety evaluation on harmful prompts and utility evaluation on math/code benchmarks
Benchmarks:
- StrongReject (Refusal / Safety (60 instructions))
- WildJailbreak (Adversarial Jailbreak (50 instructions))
- GSM8K (Math Reasoning)
- MATH-500 (Math Reasoning)
- LiveCodeBench (Code Generation)
Metrics:
- Safe@1 (Percentage of safe single responses)
- Safe@K (Binary: all K responses safe)
- ConsSafe@K (Binary: majority of K responses safe)
- Pass@1 (Accuracy for math/code)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Evaluation of baseline LRMs shows that larger models are generally safer, but none are fully safe. DeepSeek-R1 (671B) is the strongest baseline. | ||||
| StrongReject | Safe@1 | 19.2% | 84.7% | +65.5% |
| WildJailbreak | Safe@1 | 48.8% | 62.8% | +14.0% |
| Decoding strategies significantly impact safety. ZeroThink (forcing no thought) is the most effective intervention without training. | ||||
| StrongReject | Safe@1 | 35.3% | 99.3% | +64.0% |
| WildJailbreak | Safe@1 | 48.4% | 92.4% | +44.0% |
| Fine-tuning results: SAFECHAIN improves safety while preserving utility, whereas standard SFT (WJ-40K) destroys reasoning performance. | ||||
| LiveCodeBench | Pass@1 | 14.5% | 39.6% | +25.1% |
| WildJailbreak | Safe@1 | 49.6% | 61.2% | +11.6% |
Experiment Figures
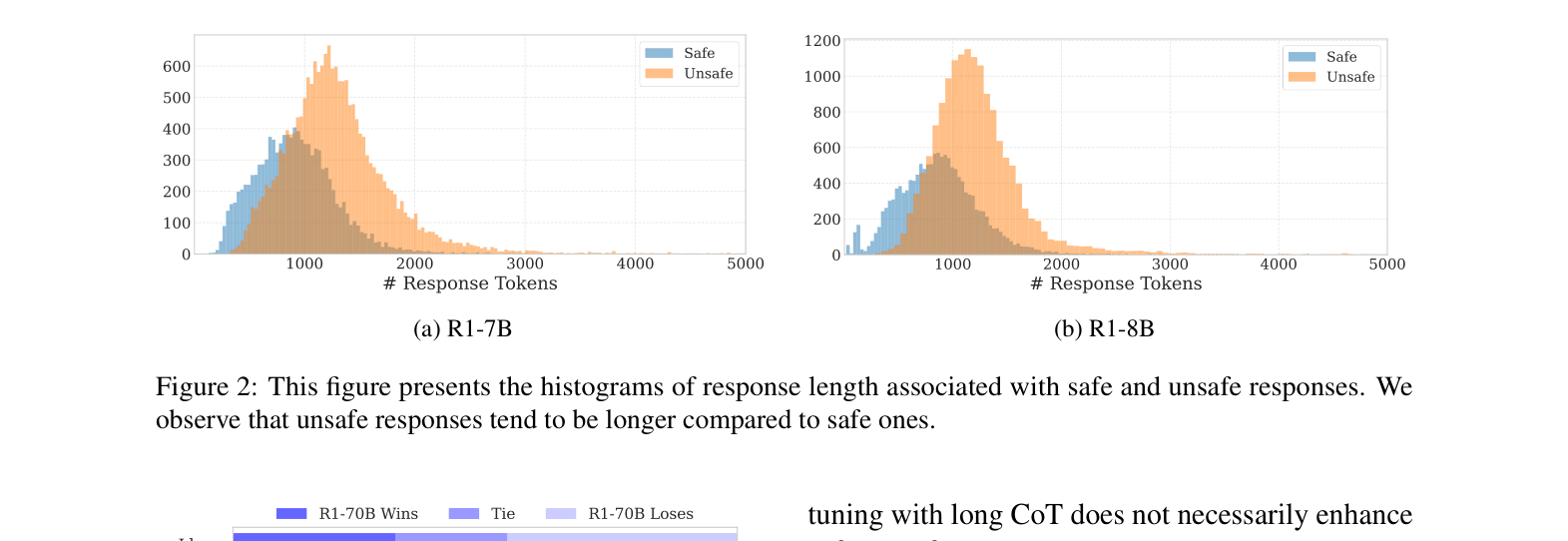
Histograms of response lengths for safe vs. unsafe responses for R1-7B and R1-8B.
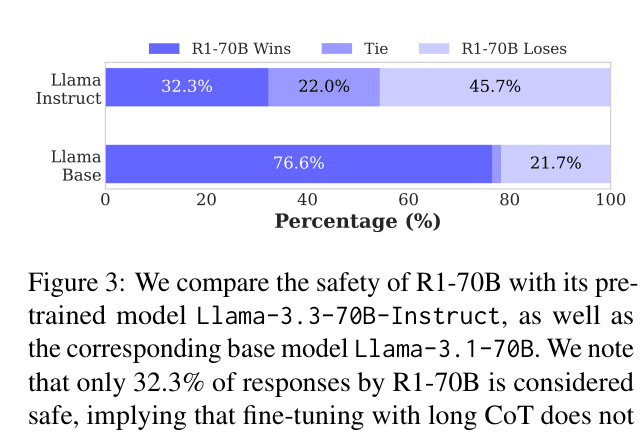
Win-rate plot comparing safety of R1-70B vs Llama-3-Base and Llama-3-Instruct.
Main Takeaways
- Long Chain-of-Thought does not inherently guarantee safety; in fact, unsafe thoughts often lead to unsafe answers (34.8% of cases in R1 models).
- Unsafe responses tend to be longer than safe ones, correlating with extended reasoning on harmful topics.
- ZeroThink (skipping reasoning) is a highly effective inference-time safety hack, suggesting models have strong base safety instincts that CoT sometimes overrides.
- SAFECHAIN fine-tuning is the only tested method that improves safety without catastrophic forgetting of reasoning capabilities (math/code).