📝 Paper Summary
Multimodal Chain-of-Thought (CoT)
Visual Question Answering (VQA)
Hallucination mitigation in Multimodal LLMs
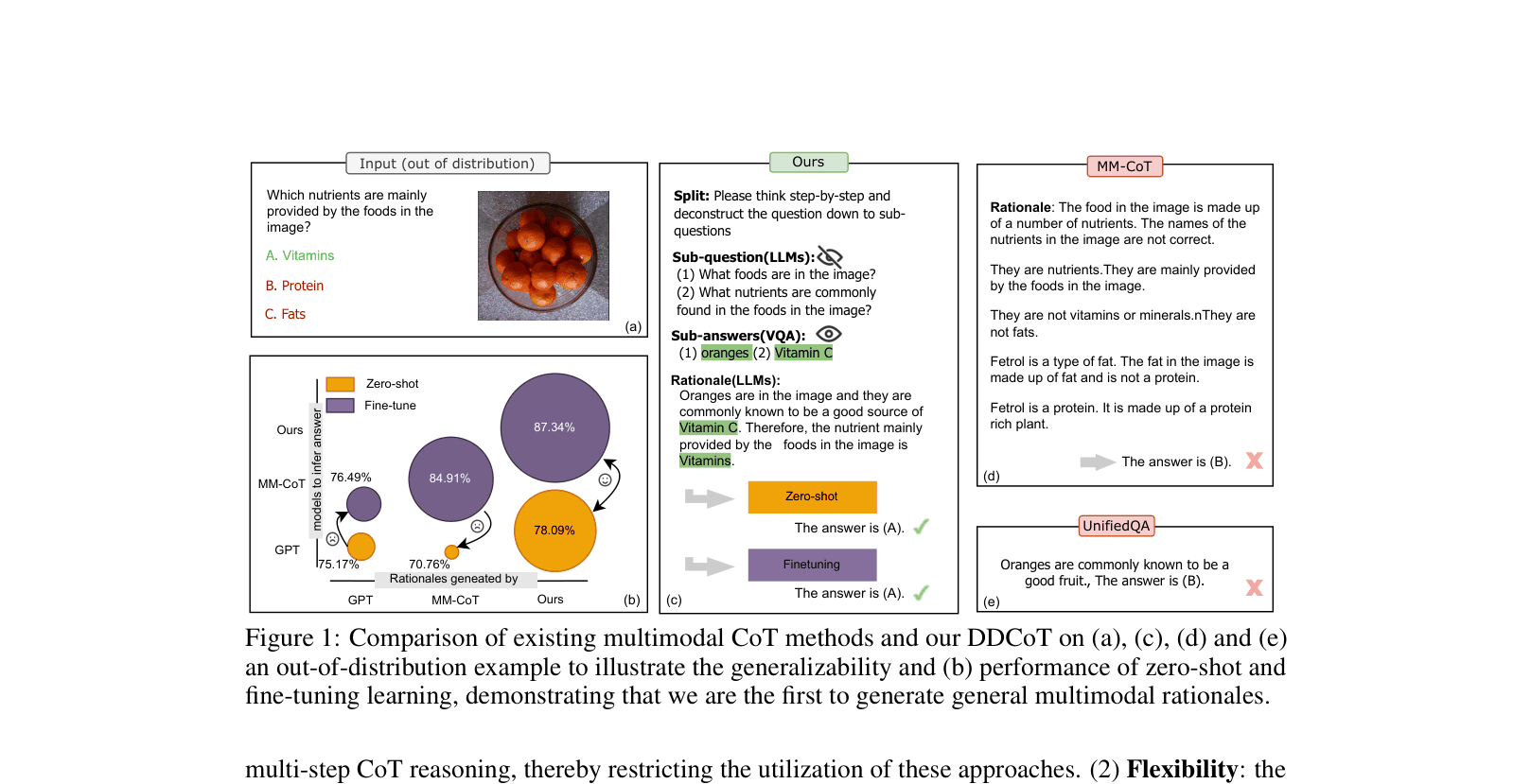
DDCoT improves multimodal reasoning by decomposing questions into text-only reasoning vs. visual recognition tasks, using negative-space prompting to handle uncertainty, and generating rationales that boost both zero-shot and fine-tuning performance.
Core Problem
Existing multimodal CoT methods rely on labor-intensive annotations, struggle with out-of-distribution generalization, and suffer from severe hallucinations when LLMs attempt to process interleaved visual-text information directly.
Why it matters:
- Current methods like MM-CoT require expensive manual rationale annotation, limiting scalability.
- LLMs often hallucinate visual details when given captions directly, inventing facts not present in the image (e.g., imagining 'kelp' in a food web).
- Rationales generated by existing methods often fail to transfer: those good for zero-shot don't help fine-tuning, and vice-versa due to different knowledge needs.
Concrete Example:
When asked to identify a secondary consumer in a food web image, a standard LLM prompted with the caption 'A food web' hallucinates specific animals like 'kelp' and 'sardines' not present in the chart. DDCoT correctly identifies the uncertainty, queries a VQA model for specific visual elements, and deduces the correct answer.
Key Novelty
Duty-Distinct Chain-of-Thought (DDCoT)
- Separates reasoning responsibilities: The LLM handles logic and decomposition, while an off-the-shelf VQA model handles specific visual recognition tasks.
- Uses 'Negative-Space Prompting': Explicitly asks the LLM to identify what it *cannot* know without seeing the image (labeling it 'Uncertain'), preventing hallucination.
- Generates rationales via a zero-shot process that are then used to either prompt LLMs (zero-shot) or guide deep-layer fusion in smaller models (fine-tuning).
Architecture
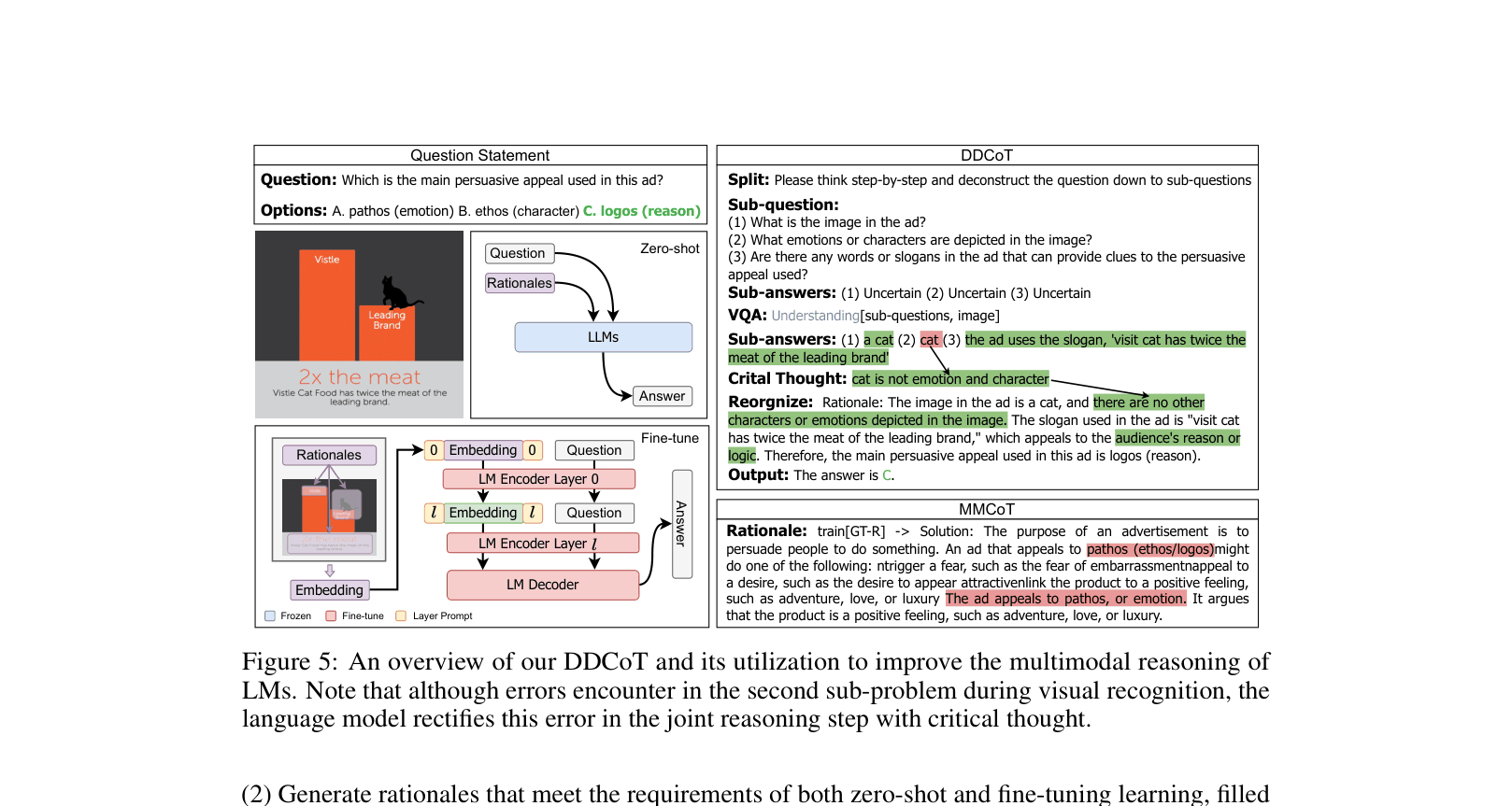
Overview of the DDCoT method, including the rationale generation process (Deconstruction -> VQA -> Joint Reasoning) and its utilization in fine-tuning.
Evaluation Highlights
- +2.53% accuracy improvement on ScienceQA (IMG split) for GPT-3 compared to standard CoT prompting.
- +8.23% accuracy improvement on ScienceQA (IMG split) for UnifiedQA fine-tuning compared to the baseline UnifiedQA model.
- Surpasses MM-CoT (which uses human-annotated rationales) by +2.43% in fine-tuning accuracy on average, despite using zero-shot generated rationales.
Breakthrough Assessment
8/10
Significant because it eliminates the need for human-annotated rationales while outperforming supervised methods. The negative-space prompting strategy effectively addresses the common hallucination problem in multimodal reasoning.