📝 Paper Summary
Chain-of-Thought (CoT) Reasoning
Hallucination Mitigation
Self-Verification
By formatting reasoning as a 'Natural Program' and decomposing verification into step-by-step checks that isolate only necessary premises, LLMs can rigorously self-verify their own deductive logic.
Core Problem
Standard Chain-of-Thought prompting often introduces hallucinations and accumulated logic errors because LLMs struggle to verify entire reasoning chains accurately when distracted by irrelevant context.
Why it matters:
- Current LLMs like ChatGPT fail to identify reasoning mistakes when verifying full chains (approx. 50% accuracy), limiting reliability in complex tasks
- Errors in early reasoning steps cause a snowball effect, compounding mistakes in subsequent steps
- Existing solutions like code-based reasoning cannot capture nuances of natural language (e.g., moral reasoning or quantifiers like 'likely')
Concrete Example:
When verifying a long reasoning chain, ChatGPT typically outputs 'Correct' regardless of validity because it considers all text (irrelevant premises) simultaneously. The paper notes it has a 50% accuracy rate on this task.
Key Novelty
Natural Program-based Step-by-Step Verification
- Decomposes verification into individual subprocesses where the model only sees the specific step and its explicitly cited necessary premises, removing distracting context
- Introduces 'Natural Program', a strict format where premises are numbered and every reasoning step explicitly cites the premise numbers it derives from (e.g., 'Step 3 (by #1, #2)')
- Uses Unanimity-Plurality Voting: samples multiple chains, filters for fully valid ones (unanimity of valid steps), and votes on the final answer (plurality)
Architecture
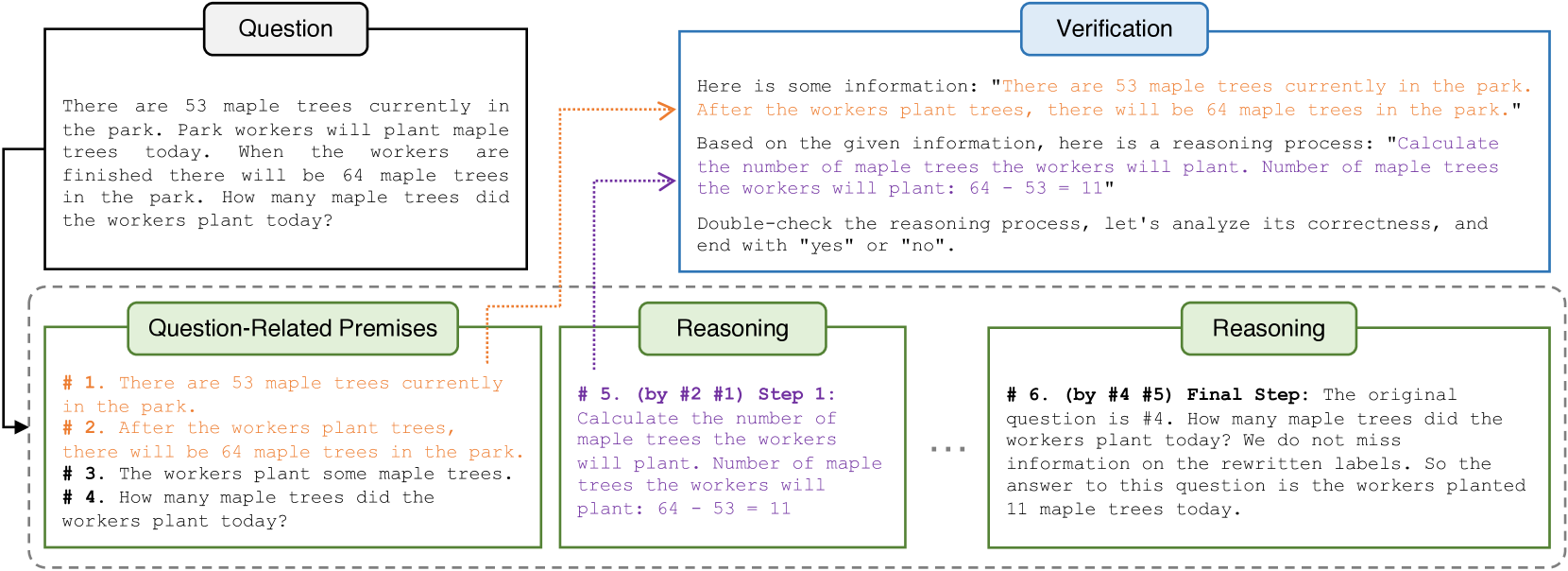
Overview of the Natural Program-based deductive reasoning and verification process (inferred from text description)
Breakthrough Assessment
7/10
Proposes a logical, structured approach to fixing CoT hallucinations without external solvers. While the provided text lacks final performance numbers, the methodology addresses a fundamental flaw in current self-verification techniques.