📝 Paper Summary
Implicit Sentiment Analysis (ISA)
Chain-of-Thought (CoT) Prompting
THOR is a three-step chain-of-thought prompting framework that enables Large Language Models to detect implicit sentiment by sequentially inferring the aspect, the underlying opinion, and finally the sentiment polarity.
Core Problem
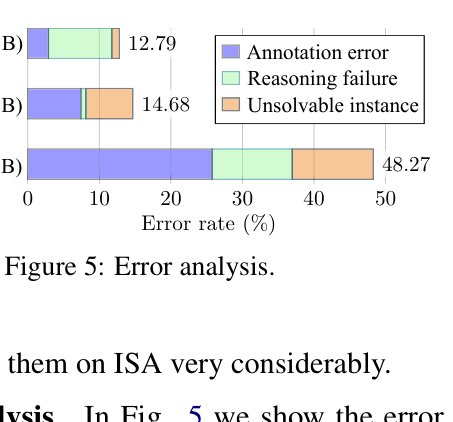
Implicit Sentiment Analysis (ISA) is difficult because input texts contain only factual descriptions without explicit opinion words, requiring common-sense reasoning to infer the latent intent.
Why it matters:
- Standard sentiment classifiers fail on texts lacking explicit emotion words (e.g., 'Try the tandoori salmon!'), predicting neutral instead of positive.
- Accurate sentiment analysis in real-world scenarios requires understanding context and hidden opinions, which traditional non-reasoning models lack.
- Existing fine-grained sentiment analysis methods struggle to connect obscure cues to sentiment polarities without explicit multi-step inference.
Concrete Example:
Given 'The new mobile phone can be just put in my pocket', a standard model predicts 'neutral'. It fails to reason that fitting in a pocket implies 'portability', which is 'convenient' (good opinion), leading to a 'positive' sentiment.
Key Novelty
Three-hop Reasoning (THOR) CoT Framework
- Decomposes implicit sentiment detection into three sequential reasoning steps: (1) inferring the specific aspect mentioned, (2) inferring the underlying opinion based on common sense, and (3) predicting the final polarity.
- Uses a self-consistency mechanism to aggregate multiple reasoning paths, selecting answers with high agreement to ensure robustness at each step.
- Incorporates a 'reasoning revising' method for supervised settings where gold labels supervise the generation of intermediate reasoning steps.
Architecture

The three-hop reasoning process of THOR compared to traditional prompting.
Evaluation Highlights
- +51.10% average F1 improvement on Zero-shot setup using GPT3 (175B) compared to the best baseline (BERT Asp+SCAPT).
- +6.65% average F1 improvement on Supervised setup using Flan-T5 (11B) compared to the best baseline.
- Scaling laws hold: Improvement scales exponentially with model size, with GPT3-175B achieving near-supervised performance in zero-shot settings.
Breakthrough Assessment
8/10
Achieves massive improvements (>50% F1) in zero-shot implicit sentiment analysis by successfully applying Chain-of-Thought reasoning, effectively solving a long-standing challenge for standard classifiers.