📝 Paper Summary
Theoretical Analysis of Transformers
Chain-of-Thought Reasoning
Theoretical analysis proving that while transformers cannot learn parity efficiently end-to-end, they can solve it efficiently when trained with Chain-of-Thought supervision or self-consistency checks.
Core Problem
Standard gradient-based training of transformers fails to learn the k-parity problem (calculating parity of a subset of bits) efficiently from examples because the gradient signal is exponentially small relative to the noise.
Why it matters:
- Large Language Models (LLMs) struggle with complex reasoning tasks like multi-hop logic or arithmetic in zero-shot settings
- Understanding how Chain-of-Thought (CoT) emerges during training is theoretically limited; existing work focuses on expressivity rather than optimization dynamics
- Parity is a canonical 'hard' problem for neural networks, representing a class of reasoning tasks that require precise composition of information
Concrete Example:
Given a 16-bit input where the output depends on the parity of bits x1, x4, and x9, a standard transformer trained on input-output pairs will fail. The proposed method decomposes this into a tree of 2-parity calculations (e.g., intermediate steps x1⊕x4), allowing the model to learn efficiently.
Key Novelty
Theoretical guarantees for CoT optimization on Parity
- Proves that transformers trained with 'teacher forcing' (supervision on intermediate reasoning steps) can learn parity in a single gradient update by exploiting modular task decomposition
- Demonstrates that even without ground-truth intermediate labels, transformers can learn parity in logarithmic time if augmented with self-consistency checks to filter 'faulty reasoning'
- Establishes a rigorous separation between the hardness of standard training (requires exponential samples/steps) and the efficiency of CoT training
Architecture
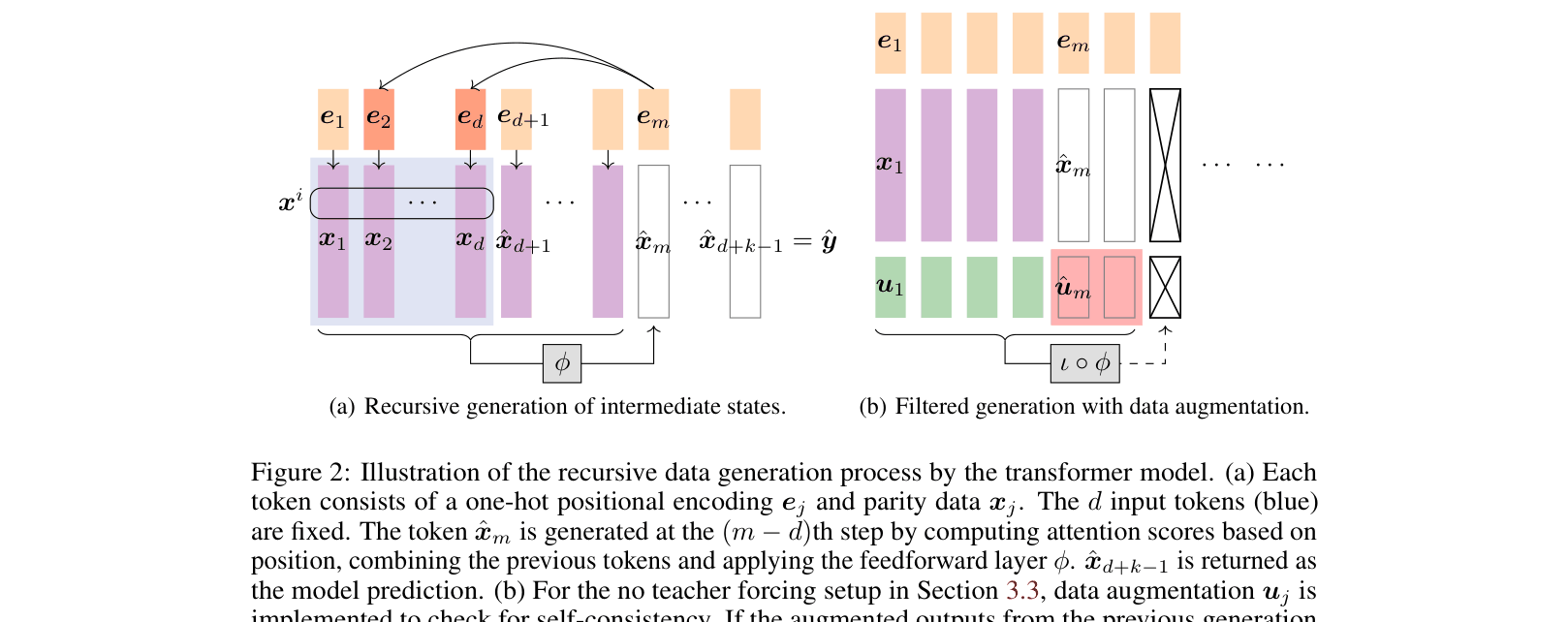
Illustration of the recursive data generation process by the transformer model for Chain-of-Thought.
Evaluation Highlights
- Transformers with CoT and teacher forcing learn parity in 1 gradient update with O(d^2+ε) samples, whereas standard training fails even with exponential queries
- Transformers with CoT and self-consistency checks (no teacher forcing) learn parity in log_2(k) iterations with high probability
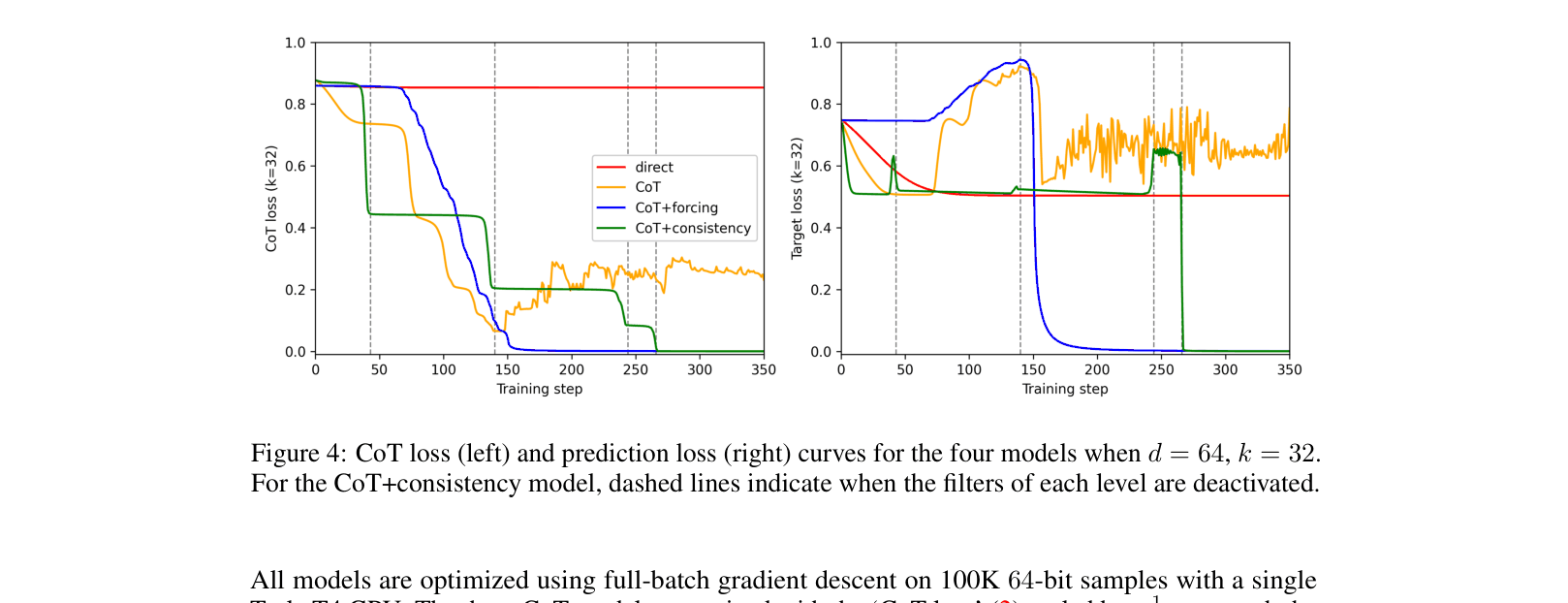
- Empirical experiments on 64-bit inputs with k=32 show standard training flatlines at 0.5 error, while CoT methods achieve near-zero error
Breakthrough Assessment
8/10
Provides the first theoretical optimization guarantees for training transformers with Chain-of-Thought on a hard reasoning task, rigorously explaining why step-by-step supervision succeeds where end-to-end training fails.