📊 Experiments & Results
Evaluation Setup
Synthetic LEGO tasks predicting final variable states after a sequence of operations.
Benchmarks:
- LEGO-Cyclic (C6) (State tracking with simply transitive group action)
- LEGO-Symmetry (S5) (State tracking with symmetry group action (NC1-complete))
Metrics:
- Accuracy (exact match of final state)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| LEGO-Cyclic (C6) | Accuracy | 100.0 | 100.0 | 0.0 |
| LEGO-Symmetry (S5) | Accuracy | 100.0 | 0.0 | -100.0 |
| LEGO-Symmetry (S5) | Accuracy | 0.0 | 100.0 | +100.0 |
Experiment Figures
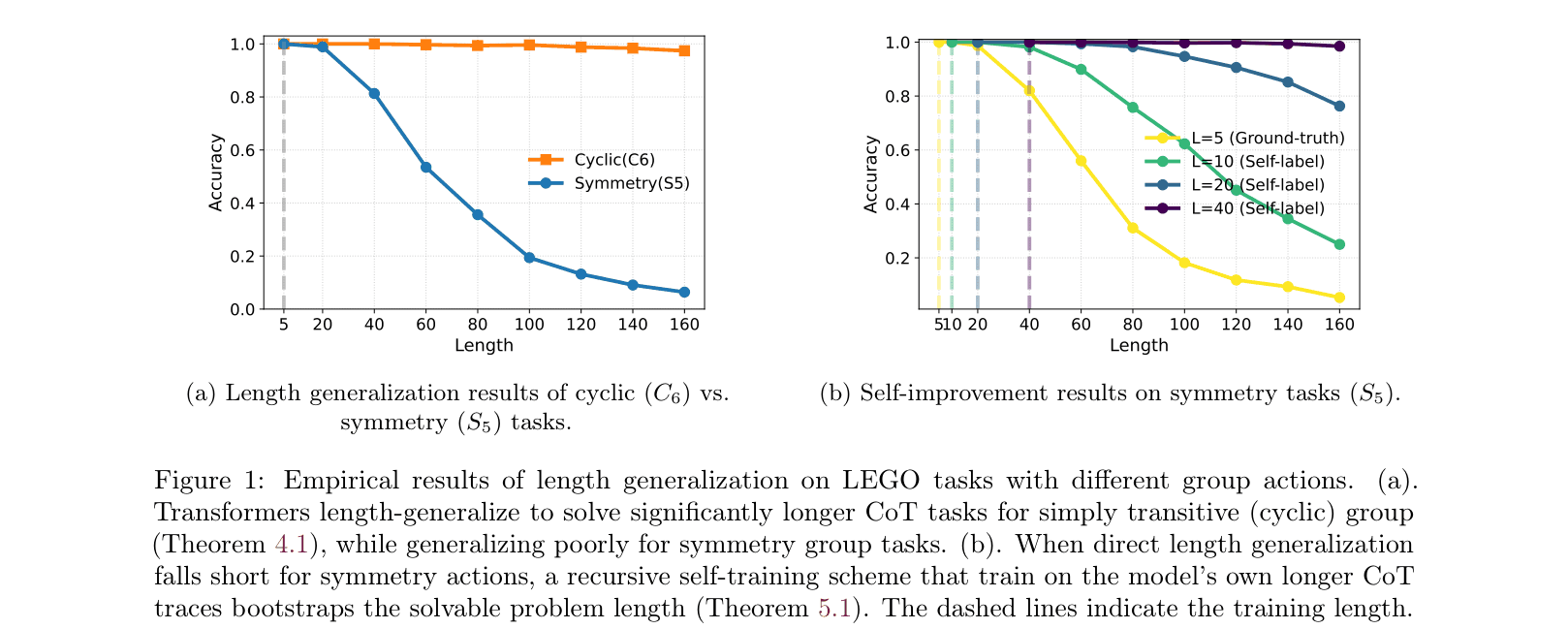
Comparison of length generalization between Cyclic (C6) and Symmetry (S5) tasks, and the effect of self-training.
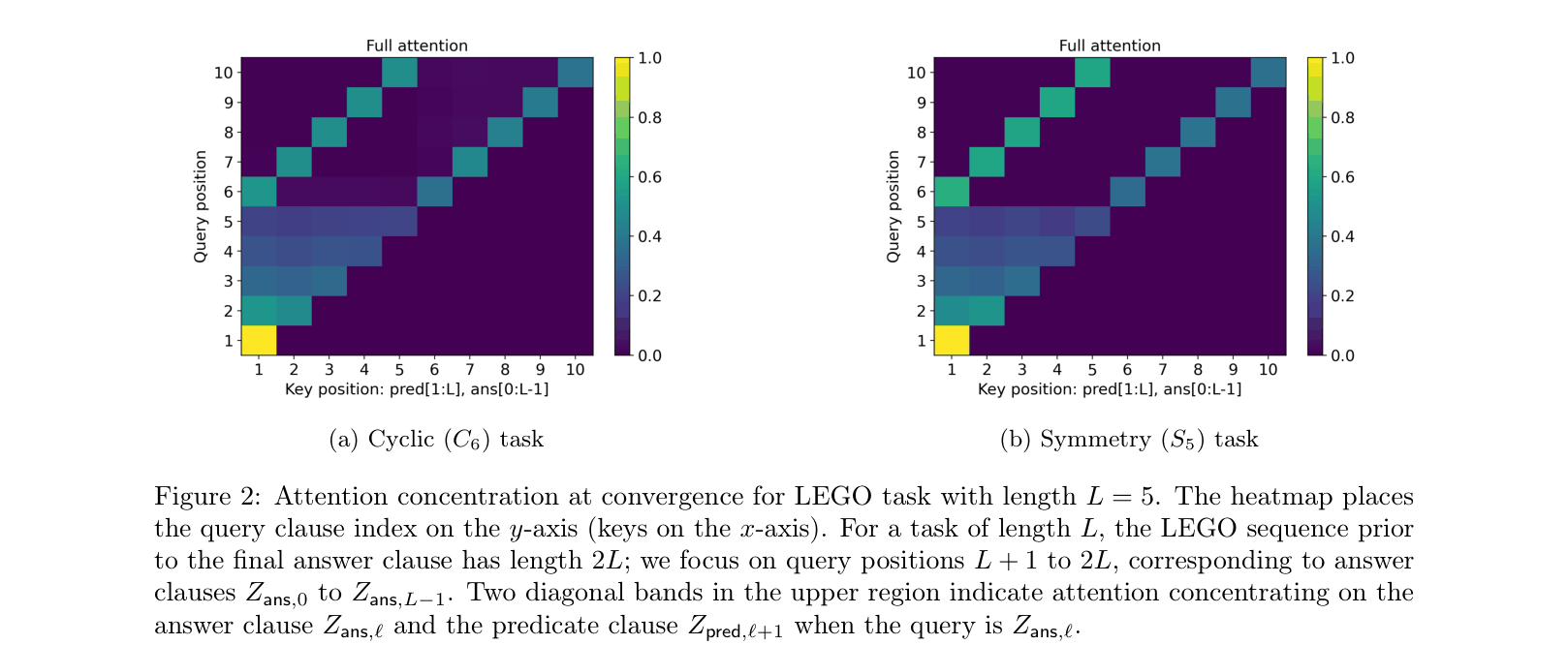
Attention maps for Cyclic vs Symmetry tasks at convergence.
Main Takeaways
- The algebraic structure of the reasoning task determines length generalization: simply transitive groups generalize naturally; symmetry groups do not.
- Attention concentration is the key mechanism: sharp attention (1-hot) enables generalization, while diffuse attention (due to distractors in symmetry groups) fails at length.
- Recursive self-training effectively bootstraps the model, allowing it to extend solvable length by using its own predictions as labels for longer sequences.