📝 Paper Summary
Prompt Engineering
Active Learning
Active-Prompt improves Chain-of-Thought reasoning by identifying and annotating the most uncertain questions from a dataset to use as task-specific few-shot exemplars.
Core Problem
Standard Chain-of-Thought prompting relies on fixed, often randomly selected human-annotated exemplars, which may not be the most effective examples for teaching the model complex reasoning tasks.
Why it matters:
- Current methods require manual engineering to craft exemplars without knowing which questions are actually helpful to the model
- Fixed sets of exemplars fail to address specific difficulties or uncertainties the model faces in different reasoning domains
- Random selection of few-shot examples often leads to suboptimal performance compared to targeted selection
Concrete Example:
In standard CoT, a model might be prompted with 8 random math problems. If the test set contains complex probability questions but the random prompts are simple addition, the model fails. Active-Prompt detects the model is uncertain about probability, selects those specific hard questions for human annotation, and uses them as prompts.
Key Novelty
Uncertainty-based Active Learning for Prompt Selection
- Instead of random examples, the system asks the LLM to answer training questions multiple times and measures uncertainty (disagreement, entropy, etc.)
- Questions with the highest uncertainty are selected for human annotation (writing reasoning chains)
- These specific, high-uncertainty questions become the few-shot exemplars for inference, effectively teaching the model where it is weakest
Architecture
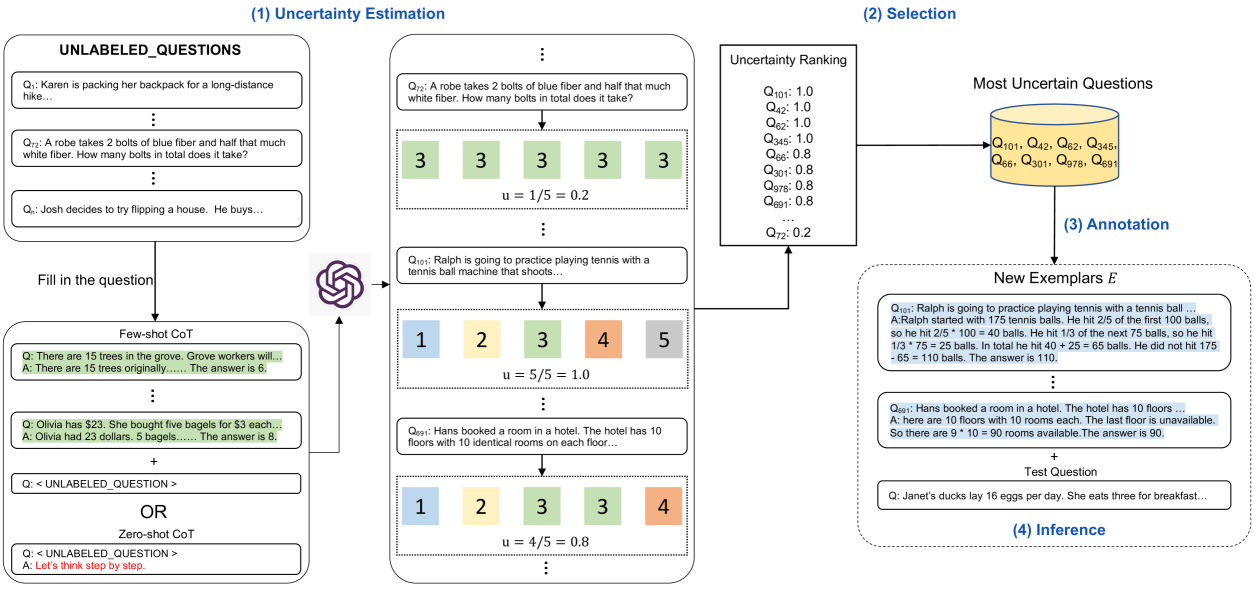
Schematic of the Active-Prompt pipeline comprising four stages: Uncertainty Estimation, Selection, Annotation, and Inference.
Evaluation Highlights
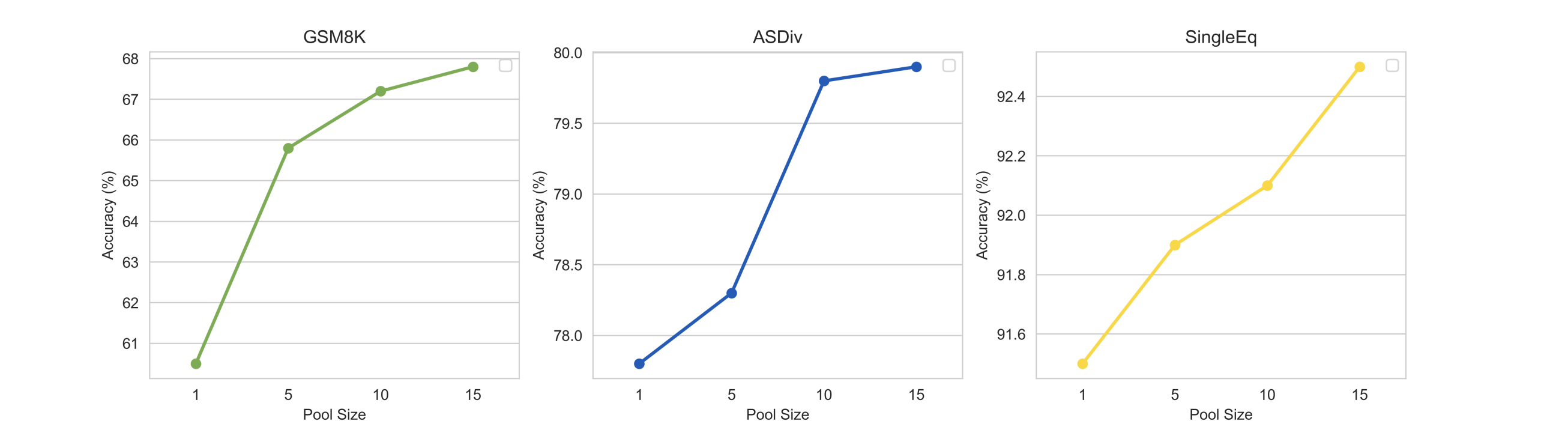
- Achieves superior performance on 8 complex reasoning datasets (arithmetic, commonsense, symbolic) compared to CoT and Self-consistency baselines
- Outperforms Auto-CoT and Random-CoT, demonstrating that active selection is more effective than clustering or random sampling
- Works effectively with multiple LLMs including code-davinci-002, text-davinci-002, and text-davinci-003
Breakthrough Assessment
8/10
Significant methodology improvement for in-context learning. Bridges active learning and prompt engineering effectively, showing that *which* examples are used matters as much as *how* they are used.