📊 Experiments & Results
Evaluation Setup
Function-level code generation validated against unit tests
Benchmarks:
- HumanEval (Python coding problems (hand-written))
- MBPP (Python coding problems (crowd-sourced))
- MBCPP (C++ coding problems)
Metrics:
- Pass@1
- Pass@3
- Pass@5
- Statistical methodology: Unbiased Pass@k estimator
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| SCoT Prompting consistently outperforms standard CoT and Few-shot prompting across all benchmarks and models, particularly in Pass@1. | ||||
| HumanEval | Pass@1 | 53.29 | 60.64 | +7.35 |
| MBPP | Pass@1 | 41.83 | 46.98 | +5.15 |
| MBCPP | Pass@1 | 53.51 | 57.06 | +3.55 |
| HumanEval | Pass@1 | 43.79 | 49.82 | +6.03 |
| Ablation studies confirm that both the explicit program structures and Input/Output definitions contribute to performance. | ||||
| HumanEval | Pass@1 | 60.64 | 55.67 | -4.97 |
| HumanEval | Pass@1 | 60.64 | 59.65 | -0.99 |
Experiment Figures
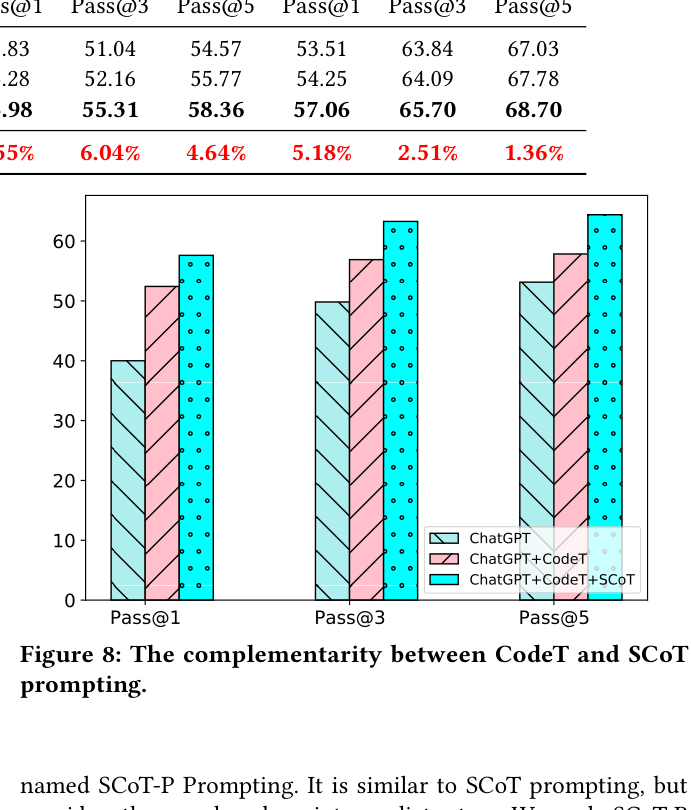
Performance curve on MBPP when combining ChatGPT, CodeT (Ranker), and SCoT.
Main Takeaways
- Structuring intermediate reasoning with explicit code-like constructs (loops, branches) significantly aids code generation compared to flat natural language.
- SCoT is language-agnostic, showing improvements in both Python (HumanEval/MBPP) and C++ (MBCPP).
- Human evaluation confirms SCoT-generated code is not just more correct, but also has fewer code smells and better maintainability.
- The approach is robust to different example seeds and annotator writing styles.