📝 Paper Summary
Fact-checking evaluation
Multi-agent simulation
Hallucination detection
Fact-Audit is a multi-agent framework that dynamically generates and updates fact-checking test cases to adaptively uncover LLM weaknesses in both verdict prediction and justification reasoning.
Core Problem
Existing automated fact-checking evaluations rely on static datasets that risk data leakage, fail to adapt to model-specific weaknesses, and often oversimplify evaluation to binary classification accuracy without assessing reasoning.
Why it matters:
- Static benchmarks (like FactCheckGP) quickly become obsolete or contaminated in pre-training data, leading to inflated performance scores (leaderboard swamping)
- Measuring only accuracy ignores whether the model arrived at the correct verdict through valid reasoning or hallucinated logic
- Manual annotation of new fact-checking scenarios is labor-intensive and cannot scale to cover the long-tail knowledge distribution of diverse LLMs
Concrete Example:
When verifying a complex claim, a model might guess the correct verdict 'Refuted' but provide a nonsensical justification. Standard accuracy metrics count this as a success, whereas Fact-Audit detects the flaw by evaluating the justification and generating new, similar test cases to probe this specific reasoning failure.
Key Novelty
Importance Sampling for Adaptive Auditing
- Treats dataset generation as an importance sampling process, where a proposal distribution is iteratively updated to focus on areas where the target model performs poorly (high error rate regions)
- Uses a multi-agent loop (Appraiser, Inquirer, Inspector, Evaluator) to autonomously discover new fact-checking scenarios and generate challenging synthetic test cases based on previous failure feedback
Architecture
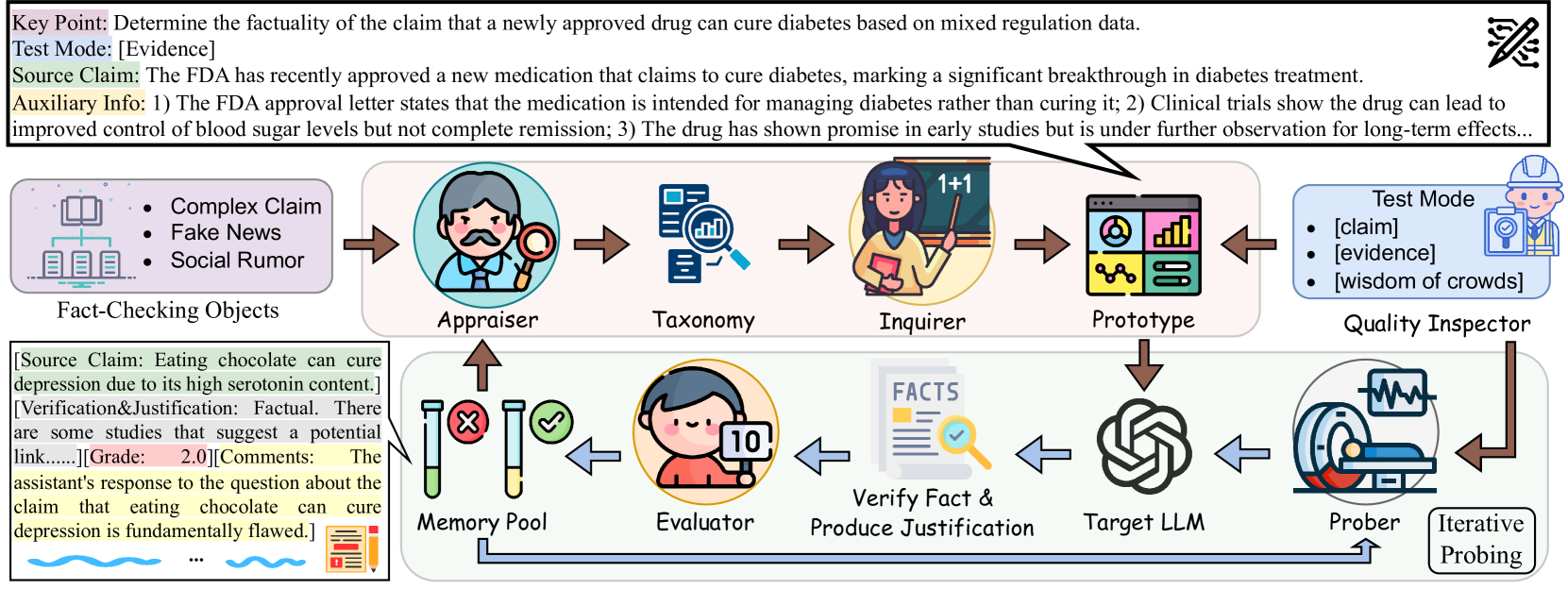
The Fact-Audit framework workflow, detailing the interaction between the four agents (Appraiser, Inquirer, Quality Inspector, Evaluator) and the iterative feedback loop.
Evaluation Highlights
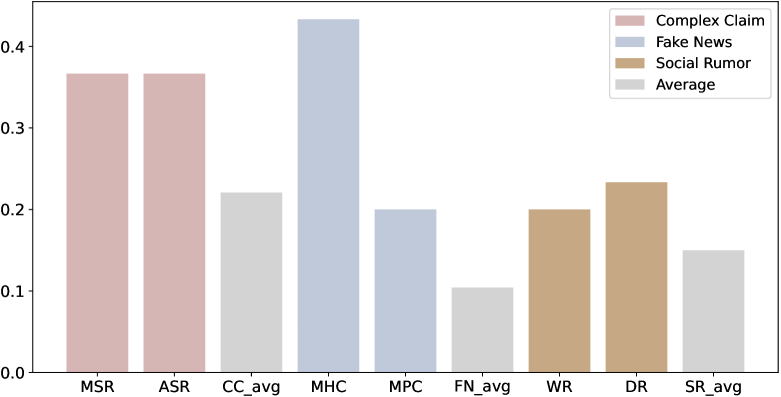
- Fact-Audit reveals that GPT-4o's performance drops significantly (e.g., -10% to -20% accuracy) on adaptively generated cases compared to static prototypes, exposing hidden weaknesses
- Identifies that open-source models like Llama-3-70B-Instruct lag behind GPT-4o by notable margins in justification quality, even when verdict accuracy is comparable
- Demonstrates that iterative probing uncovers twice as many failure cases in 'wisdom of crowds' scenarios compared to standard random sampling
Breakthrough Assessment
8/10
Significant shift from static to dynamic evaluation for fact-checking. The formalization as importance sampling and the focus on justification quality address major gaps in current benchmarks.