📝 Paper Summary
Referring Expression Comprehension (REC)
Multimodal Large Language Models (MLLMs)
Rex-Thinker reformulates object referring as a retrieval task using explicit Chain-of-Thought reasoning to verify candidate objects step-by-step, significantly reducing hallucinations and improving interpretability.
Core Problem
Most referring expression models either directly regress coordinates or retrieve boxes implicitly, lacking interpretable reasoning and failing to reject expressions when no matching object exists (hallucination).
Why it matters:
- Current black-box models are unverifiable; users cannot trace why a specific box was selected
- High hallucination rates in existing models reduce reliability in real-world applications where targets might be missing
- Direct coordinate regression struggles with complex reasoning tasks that require checking attributes step-by-step
Concrete Example:
When asked to locate 'the person wearing a blue shirt' in an image where no such person exists, standard models often force a prediction on a random person. A grounded model should inspect each person, find no match, and explicitly output a rejection.
Key Novelty
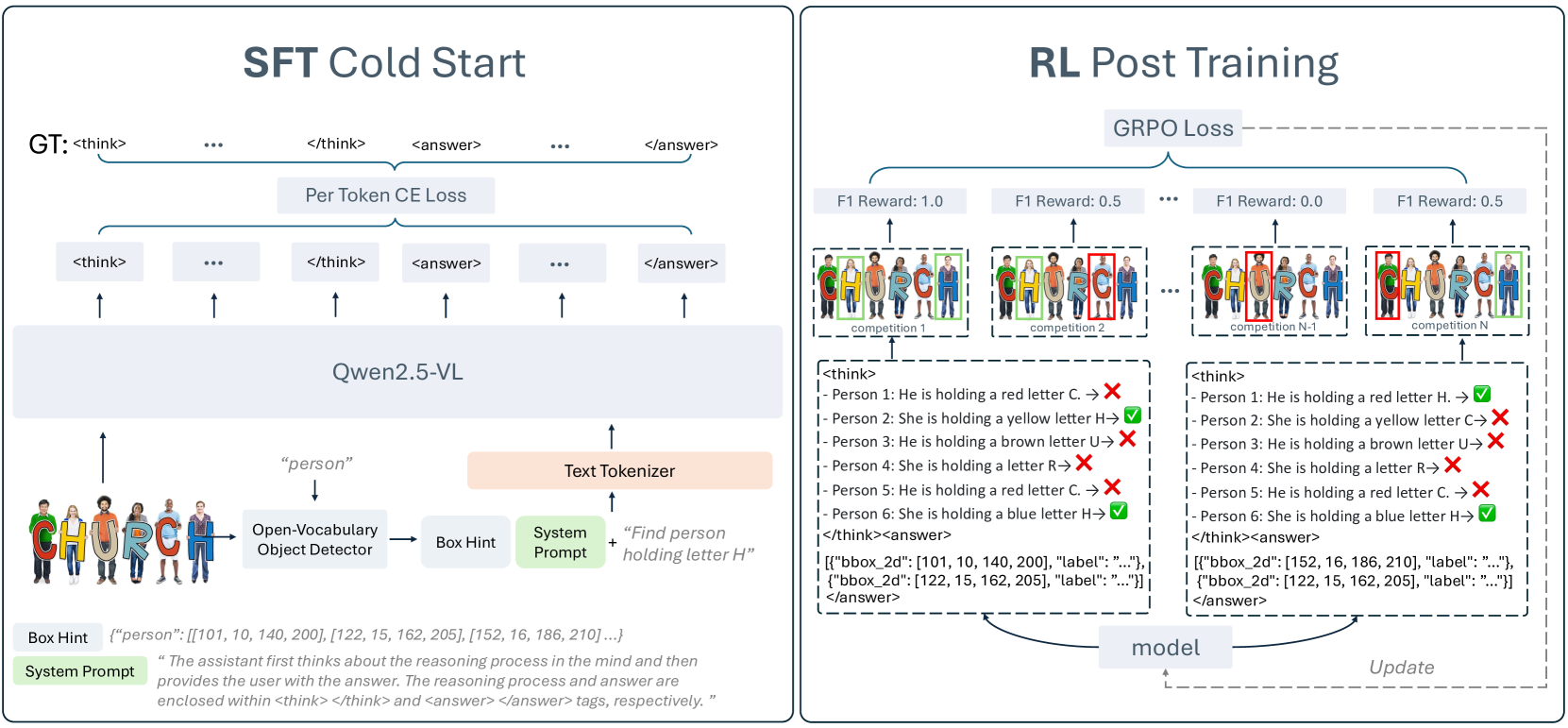
Planning-Action-Summarization CoT for Object Referring
- Reformulates referring as a retrieval process: an external detector provides candidate boxes (hints), and the MLLM reasons about each one
- Structured CoT: The model explicitly plans subgoals, acts by checking specific box hints against the text, and summarizes findings to select the answer
- Two-stage training: Cold-start SFT on a new CoT dataset followed by GRPO (Group Relative Policy Optimization) to reinforce correct reasoning paths
Architecture

The inference pipeline of Rex-Thinker comparing it to previous methods. It illustrates the Planning -> Action -> Summarization workflow.
Evaluation Highlights
- +13.6% accuracy improvement on HumanRef-Reasoning subset compared to Chat-Rex-7B
- Achieves 86.8% accuracy on HumanRef-Rejection subset, significantly outperforming baselines that struggle to abstain
- Zero-shot generalization to RefCOCOg is strong (86.2% precision), and further fine-tuning with GRPO yields additional gains (+0.7%)
Breakthrough Assessment
8/10
Strong contribution in applying the 'thinking' paradigm (CoT + RL) to vision-language grounding. The construction of a dedicated CoT dataset and the demonstration of verifiable reasoning + rejection capability are significant steps forward.