📊 Experiments & Results
Evaluation Setup
Mathematical reasoning on standard benchmarks
Benchmarks:
- GSM8K (Grade school math word problems)
- MATH (Challenging mathematics problems)
Metrics:
- Accuracy
- Statistical methodology: Fixed seed (42) with greedy decoding used to ensure deterministic results; means/std devs not reported.
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Retrieval-based few-shot methods show negligible improvement over Zero-shot baselines for strong models. | ||||
| GSM8K | Accuracy gain | Not reported in the paper | Not reported in the paper | +0.2% |
Experiment Figures
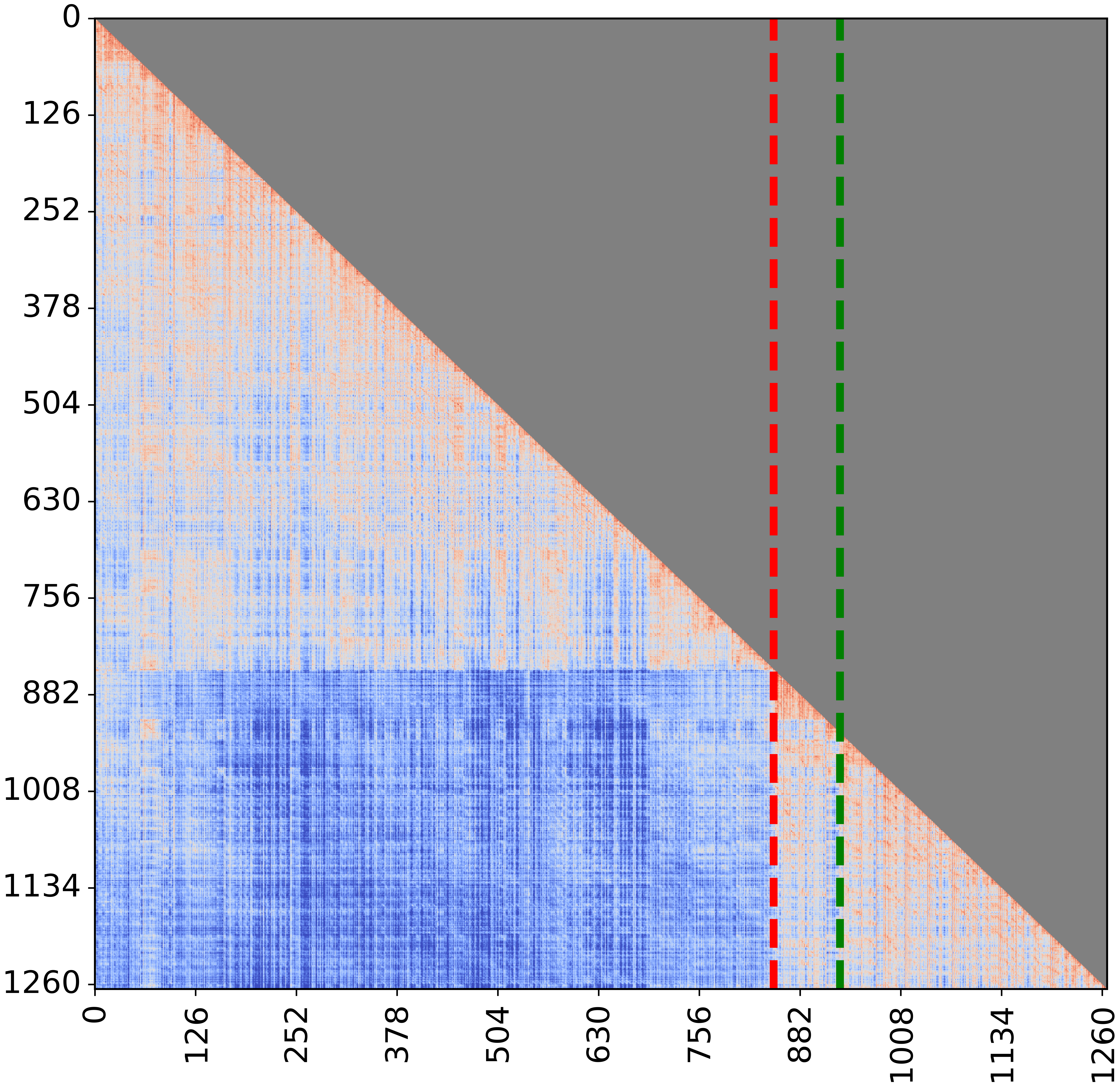
Attention visualization of Qwen2.5-7B on GSM8K under Few-shot settings

Ablation study on exemplar noise (replacing tokens in exemplars with random ones)
Main Takeaways
- Correcting evaluation bias (extracting answers from \boxed{}) dramatically improves Zero-shot scores, showing that previous gaps between Zero-shot and Few-shot were largely artifacts of parsing failures.
- For strong models (Qwen2.5, LLaMA-3), adding traditional CoT exemplars yields no significant reasoning improvement over Zero-shot CoT.
- Enhanced exemplars generated by superior models (DeepSeek-R1, Qwen2.5-Max) also fail to improve performance, as strong models tend to ignore the exemplar content.
- Ablation studies with noisy exemplars (50% token replacement) show minimal performance drops, confirming that models do not rely on the informational content of the exemplars.
- Weak or older models (LLaMA-2-7B, Qwen-7B) *do* benefit from Few-shot CoT, indicating that the ineffectiveness of CoT exemplars is specific to recent, highly capable models.