📝 Paper Summary
Long-context video understanding
Video Question Answering (VideoQA)
Temporal Chain of Thought improves long-video understanding by using the VLM itself to iteratively select relevant frames before answering, rather than processing the entire video at once.
Core Problem
Long-context Vision-Language Models (VLMs) struggle to effectively leverage their full context window, often getting overwhelmed by irrelevant distractors in long videos despite technically supporting thousands of frames.
Why it matters:
- Processing longer contexts can saturate or degrade accuracy as models get confused by irrelevant content
- Existing long-video methods often rely on complex ensembles (separate captioners, LLMs) or auxiliary tools (detection, OCR), rather than using the VLM's native capabilities
- Standard inference is computationally limited by the context window, making it impossible to process very long videos (e.g., >1 hour) without heavy subsampling
Concrete Example:
For the question 'On what floor is the washing machine?', a standard VLM might be distracted by the many rooms shown in a long video. The proposed method first extracts frames showing the washing machine and the stairs/exterior to deduce the floor, removing irrelevant kitchen or bedroom footage.
Key Novelty
Self-Reflective Visual Context Curation (Temporal Chain of Thought)
- Decomposes video QA into two steps using a single VLM: (1) Select relevant frame indices based on the question, and (2) Answer the question using only those selected frames.
- Uses a 'Dynamic-Segment' approach to handle arbitrarily long videos by processing segments independently and aggregating results, decoupling video length from the model's context limit.
- Treats selected video frames as 'visual thoughts,' analogous to textual Chain-of-Thought, allowing the model to focus reasoning on relevant evidence.
Architecture
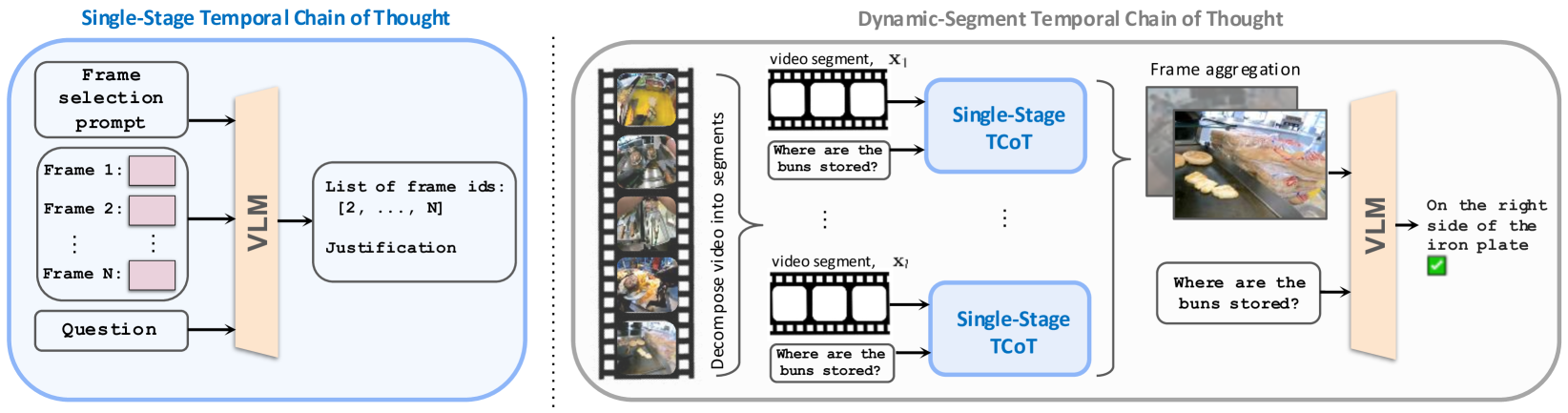
The Dynamic-Segment Temporal Chain of Thought inference pipeline.
Evaluation Highlights
- Outperforms standard inference with a 700K token context window by 2.8 points on LVBench (videos >1 hour) while using only a 32K context budget.
- Achieves state-of-the-art results on 4 diverse video question-answering benchmarks, showing consistent improvements across 3 different VLMs.
- Improves accuracy by 11.4 points on LVBench (avg 68 min videos) compared to standard inference with the same 32K token budget.
Breakthrough Assessment
8/10
Significantly improves long-video understanding by porting inference-time compute scaling (CoT) to the visual domain. Elegantly solves the 'lost-in-the-middle' problem for video without external models.