📝 Paper Summary
Medical Question Answering
Chain-of-Thought Reasoning
Clinical Decision Support
The paper introduces a prompt-driven framework for open-ended medical QA that mimics clinical incremental reasoning and uses a verifier model to select the best diagnosis from generated candidates.
Core Problem
Existing medical QA datasets and prompts rely on multiple-choice formats (MCQ) and eliminative reasoning, which do not reflect real-world clinical scenarios where doctors must generate diagnoses from open-ended patient histories without pre-set options.
Why it matters:
- Real-life clinical practice involves prospective, incremental reasoning rather than retrospective elimination of options
- Current LLM benchmarks (MedQA-USMLE) rely on 4-option MCQs, limiting their utility for open-ended patient queries in deployed healthcare systems
- Standard Chain-of-Thought prompts often bias models towards elimination strategies rather than constructive clinical diagnosis
Concrete Example:
In a standard setup, a model is given a patient history and options (A, B, C, D) and asked to pick one. In a real clinic, a doctor sees only the history and must derive 'Eplerenone' from scratch. Standard prompts struggle to generate this without options or use artificial elimination logic even when options are hidden.
Key Novelty
ClinicR (Clinical Reasoning Prompt) + Forward-Backward Verification
- Proposes ClinicR, a 5-shot prompt that mimics a doctor's incremental reasoning: reading history, forming initial hypotheses, updating them with new findings, and concluding a final diagnosis
- Introduces a Forward-Backward approach: first generating multiple potential diagnoses (Forward) using ClinicR, then selecting the best one (Backward) using a trained Verifier (Reward Model)
Architecture
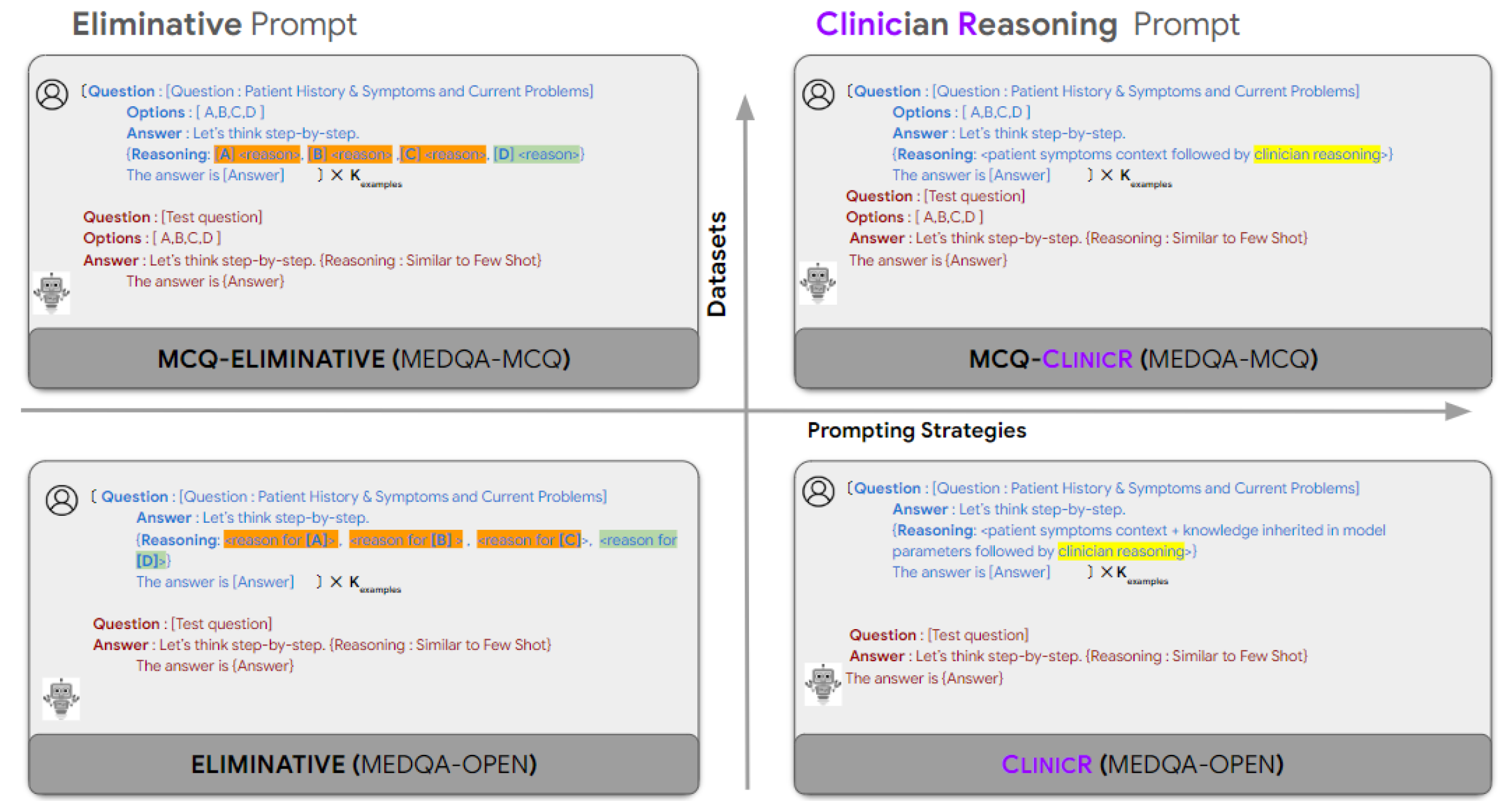
Comparison of Eliminative vs. ClinicR prompting strategies in both Open and MCQ settings
Evaluation Highlights
- Medical experts agreed with 87% of answers generated by Llama-2-70B-chat using the Forward-Backward ClinicR approach on the new MedQA-Open dataset
- ClinicR outperforms the state-of-the-art eliminative CoT prompt by substantial margins on open-ended tasks (83% vs 56% expert agreement on Llama-2-7B-chat)
- The verifier-based selection achieves 90% expert agreement on real-world ClinicianCases with Llama-2-7B-chat
Breakthrough Assessment
7/10
Strong practical contribution by shifting from MCQ to open-ended medical QA with expert verification. The method is intuitive and effective, though primarily a prompt engineering and reranking innovation rather than a fundamental architectural shift.
